




- @weixin_43941364
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
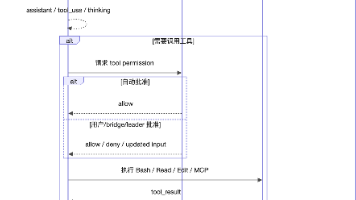
摘要:Harness Engineering是确保LLM在真实环境中稳定运行的系统工程,Claude Code源码展示了其核心要素:1)构建包含环境、规则、记忆的工作空间;2)定义工具能力与权限边界;3)通过Agent Loop实现多轮自主决策;4)支持长期运行的会话恢复机制;5)独立验证系统确保结果可靠;6)拆分子智能体实现角色分工。其实质是将上下文、工具、状态管理等整合为可编程的运行时系统,使
文章目录前言一、使用点对点信道的数据链路层1、数据链路和帧2、三个基本问题2.1、封装成帧2.2、透明传输2.3、差错检测二、点对点协议PPP1、PPP协议的特点1.1、PPP协议应满足的需求1.2、PPP协议的组成2、PPP协议的帧格式2.1、各字段的意义2.2、字节填充2.3、零比特填充3、PPP协议的工作状态三、使用广播信道的数据链路层前言数据链路层使用的信道主要有两种类型:点对点信...
Dify 流式数据在 UniApp 中的实现方案摘要:通过 uni.request 的 enableChunked 参数接收流式数据,解析时需注意 ArrayBuffer 转 UTF-8 文本、处理粘包分割、区分事件类型。核心逻辑是逐个解析 data: 开头的 JSON 数据包,将 answer 字段内容追加到当前消息而非替换。关键点包括正确解码中文、处理不同事件类型(message/messag

摘要:Harness Engineering是确保LLM在真实环境中稳定运行的系统工程,Claude Code源码展示了其核心要素:1)构建包含环境、规则、记忆的工作空间;2)定义工具能力与权限边界;3)通过Agent Loop实现多轮自主决策;4)支持长期运行的会话恢复机制;5)独立验证系统确保结果可靠;6)拆分子智能体实现角色分工。其实质是将上下文、工具、状态管理等整合为可编程的运行时系统,使
问题描述从 http://www.zuihaodaxue.cn/ 网站中爬取数据,获取世界大学学术排名(Top10)爬取的数据保存为Excel文件(.xlsx)进一步考虑,数据可视化输出(附加)问题分析换汤不换药,相关解释请查阅这篇文章:Python:使用爬虫获取中国最好的大学排名数据(爬虫入门)这里就不在赘述了,直接写代码。结果展示不过我觉得转化为饼图会更直观一些,但是那样会有子图,如果有时间我
问题描述在 Spring 项目启动的时候报错如下org.springframework.util.xml.SimpleSaxErrorHandler warning警告: Ignored XML validation warningorg.xml.sax.SAXParseException; systemId: http://www.springframework.org/schema/tx/sp
org.springframework.web.client.ResourceAccessException: I/O error on POST request for “http://localhost:9411/api/v2/spans”: connect timed out; nested exception is java.net.SocketTimeoutException: conn
Dify 流式数据在 UniApp 中的实现方案摘要:通过 uni.request 的 enableChunked 参数接收流式数据,解析时需注意 ArrayBuffer 转 UTF-8 文本、处理粘包分割、区分事件类型。核心逻辑是逐个解析 data: 开头的 JSON 数据包,将 answer 字段内容追加到当前消息而非替换。关键点包括正确解码中文、处理不同事件类型(message/messag
使用 PowerDesigner 做数据库设计,主要用到两个大的模型:第一个是 CDM:概念模型;第二个是 PDM:物理模型。整体的步骤如下:先创建 CDM;然后把 CDM 转化成 PDM ;最后把 PDM 转化成数据库 sql 执行语句;还可以把 PDM 转化成 word 文档。所以本文也分为 4 个步骤介绍。一、创建概念模型打开之后,选择创建概念模型:修改名称之后点击 OK:可以在 Domai
问题描述请使用 Python 爬取最好大学网的 大学排名数据 ,并保存为 CSV 和 Excel 格式。结果展示以爬取前 10 名大学为例:解决思路目标网站:软科中国最好大学排名2019使用 Python 的 BeautifulSoup 库:BeautifulSoup官方文档这里主要使用了 BeautifulSoup 库,该库功能十分强大,我只使用了它不到 1% 的功能。更多的功...