
写文章




- @weixin_43845924
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
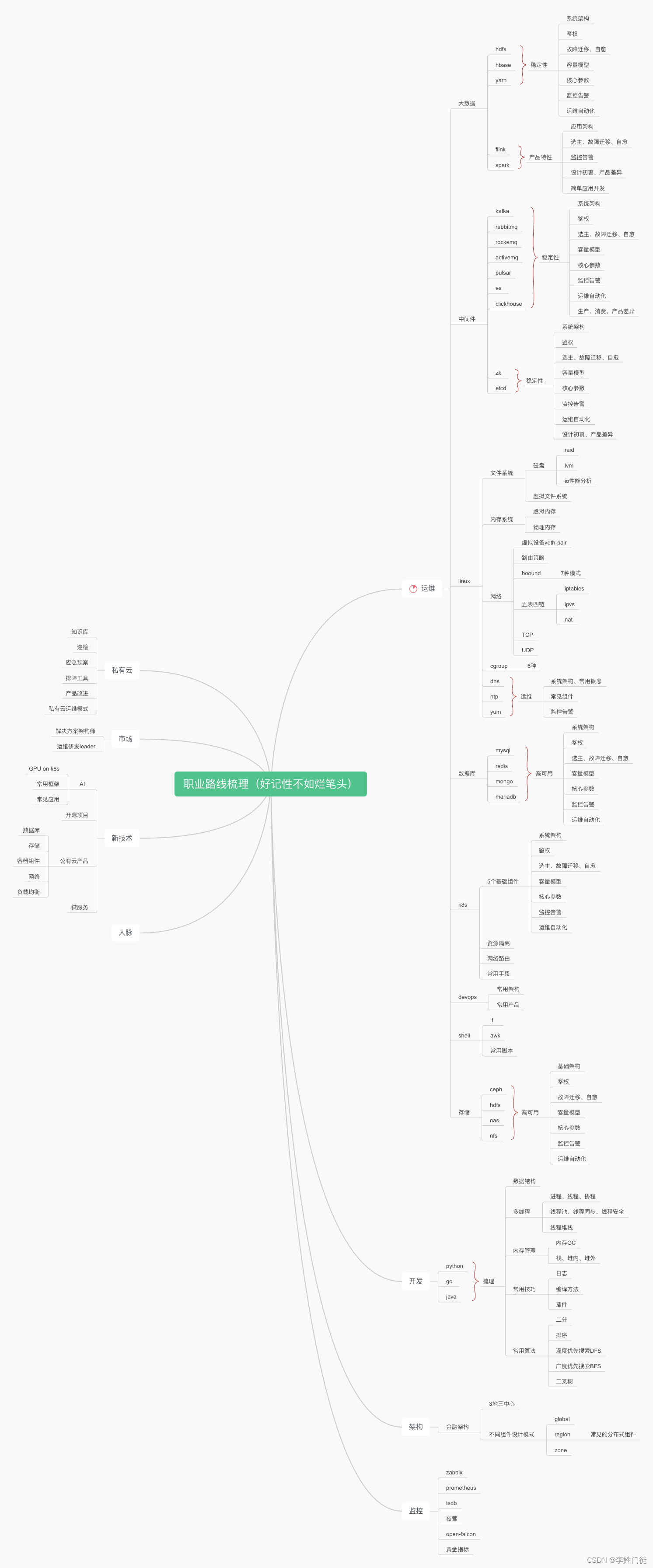
运维职业路线技术栈梳理
梳理运维同学的职业发展设计的技术栈路线,共勉
GPU通用计算介绍
谈到 GPU (Graphics Processing Unit,图形显示卡)大多数人想到的是游戏、图形渲染等这些词汇,图形处理确实是 GPU 的一大应用场景。然而人们也早已关注到它在通用计算上的巨大潜力,并提出了 GPGPU (General-purpose computing on graphics processing units, 图形处理器上的通用计算) 概念。到随着大数据处理、深度学习

KAFKA监控方法以及核心指标
探讨kafka的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。

RabbitMQ监控方法以及核心指标
探讨rabbitmq的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。

SRE关于稳定治理的工作思考
SRE(Site Reliability Engineering,站点可靠性/稳定性工程师),与普通的开发工程师(Dev)不同,也与传统的运维工程师(Ops)不同,SRE更接近是两者的结合,也就是2008年末提出的一个概念:DevOps,这个概念最近也越来越流行起来。SRE模型是Google对Dev+Ops模型的一种实践和拓展(可以参考《Google运维解密》一书),SRE这个概念我比较喜欢,因为

到底了