- @weixin_41605937
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
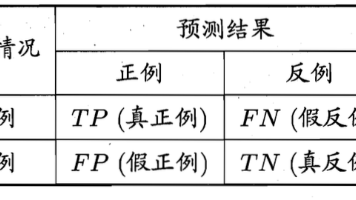
本文主要介绍了机器学习中的模型评估与选择。首先阐述了经验误差与过拟合的概念及关系,指出过拟合是模型在训练集上表现好但在测试集上表现差的现象,经验误差低不等于测试误差低,目标是降低泛化误差。接着介绍了测试数据划分方案,包括交叉验证、留出法、自助法等,并探讨了模型调参、最终模型选择等内容。还涉及了二分类模型评价指标,如查准率、查全率、F1/Fn度量,ROC与AUC,代价敏感错误率与代价曲线,以及比较检
摘要本文将介绍的有关于的paddle的实战的相关的问题,并分析相关的代码的阅读和解释。并扩展有关于的python的有关的语言。介绍了深度学习步骤: 1. 数据处理:读取数据 和 预处理操作 2. 模型设计:网络结构(假设) 3. 训练配置:优化器(寻解算法) 4. 训练过程:循环调用训练过程,包括前向计算 + 计算损失(优化目标) + 后向传播 5. 保存模型并测试:将训练好的模型保存。手写数字识

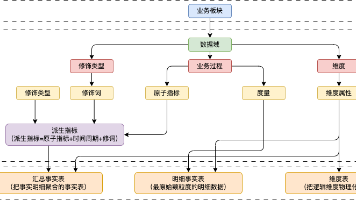
数据建模设计是数据治理体系中的关键组成,承载着数据标准化、资产化与高质量使用的核心目标。本文从治理视角出发,深入探讨数据建模在保障企业数据一致性、复用性和共享性方面的重要作用。文章首先梳理了建模的三层体系:概念模型、逻辑模型与物理模型,并分析它们在治理流程中的职责分工与协同机制。接着,重点介绍了维度建模(如星型、雪花模型)与范式建模的特点与适用场景,特别是在大数据环境下的实践差异。在建模规范方面,
摘要R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标。与R-CNN系列算法不同,YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。另外,YOLOv3算法产生的预测框数目
摘要本文主要通过使用的PaddlePaddle用于实现的图像分类的目标的。并设计与优化的相关的模型。该问题主要来源是的:https://www.kaggle.com/c/cassava-leaf-disease-classification问题背景作为非洲第二大碳水化合物供应国,木薯是小农种植的重要粮食安全作物,因为它可以承受恶劣的条件。撒哈拉以南非洲至少有80%的家庭农场都种植这种淀粉状的根,但

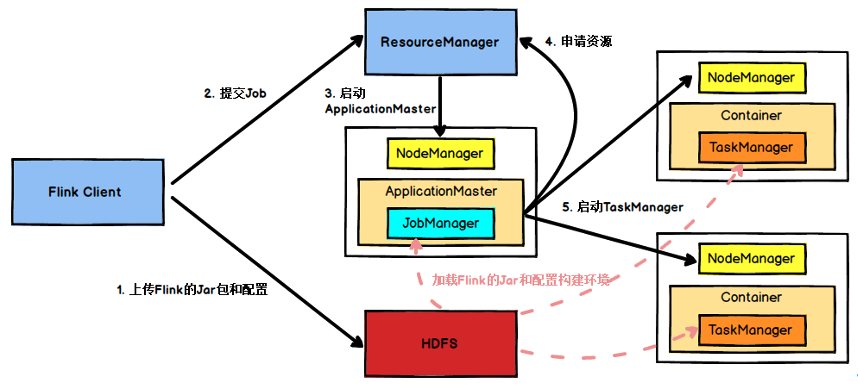
Apache Flink 是一个强大的开源框架和分布式处理引擎,专门用于对无界和有界数据流进行有状态计算。Flink 支持高吞吐量、低延迟的实时数据流处理,同时也能够高效地处理批处理任务。其核心特点包括事件时间处理、有状态操作、容错机制,以及能够在各种常见的集群环境中运行,如 Hadoop、Kubernetes 和自定义集群。Flink 还具有高度可扩展性,能够处理从小规模到大规模的数据集,同时保
摘要在CICD的流程中对于的代码检查是必要的,在工程届中Sonarqube是必不可少的工作,在构建CICD的系统架构中Sonarqube能帮助我们实现相关的代码检查工作。接下来我介绍的Sonarqube的构建个使用,同时与github jeknins等工具一起构建CICD系统。Sonarqube的简介Sonarqube在doceker构建Sonarqube在docker中的集群构建Sonarqub
这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的需求、评分卡模型的数据量要求,以及个人消费贷场景下的数据量分析等内容,旨在为机器学习实践提供数据方面的思考与经验。

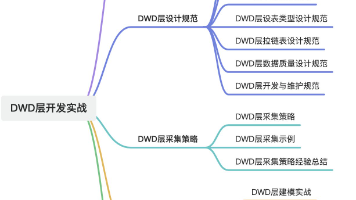
本文主要介绍了离线数仓项目中电商域DWD层的开发实战。DWD层是数据仓库架构中的明细数据层,对ODS层的原始数据进行清洗、规范、整合与业务建模。它具有数据清洗、标准化、业务建模、整合、维度挂载等作用,常见设计特征包括一致性、明细级建模、保留历史记录等。文中还给出了交易支付场景下的DWD层表示例,以及DWD层设计规范、采集策略、实战示例和数据思考等内容。
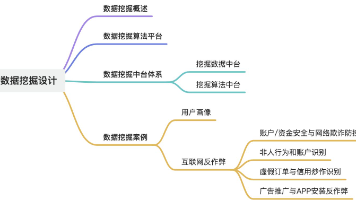
本文主要介绍了阿里巴巴在大数据治理域中的数据挖掘设计。随着数据量的爆炸式增长,阿里巴巴从使用传统的商业挖掘软件,发展到构建自己的机器学习算法平台,以应对海量数据的挖掘需求。文章概述了数据挖掘的重要性,介绍了阿里巴巴数据挖掘算法平台的发展历程、架构和功能,以及数据挖掘中台体系的构建。最后,通过用户画像和互联网反作弊等案例,展示了数据挖掘在商业中的应用价值。