- @weixin_41367158
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
例如语句GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge),校验OVER子句时需要校验所有的 Edge type,如果 Edge type 包含 like和serve,该语句会展开为GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(ed

【代码】debian设置软件源为阿里云。

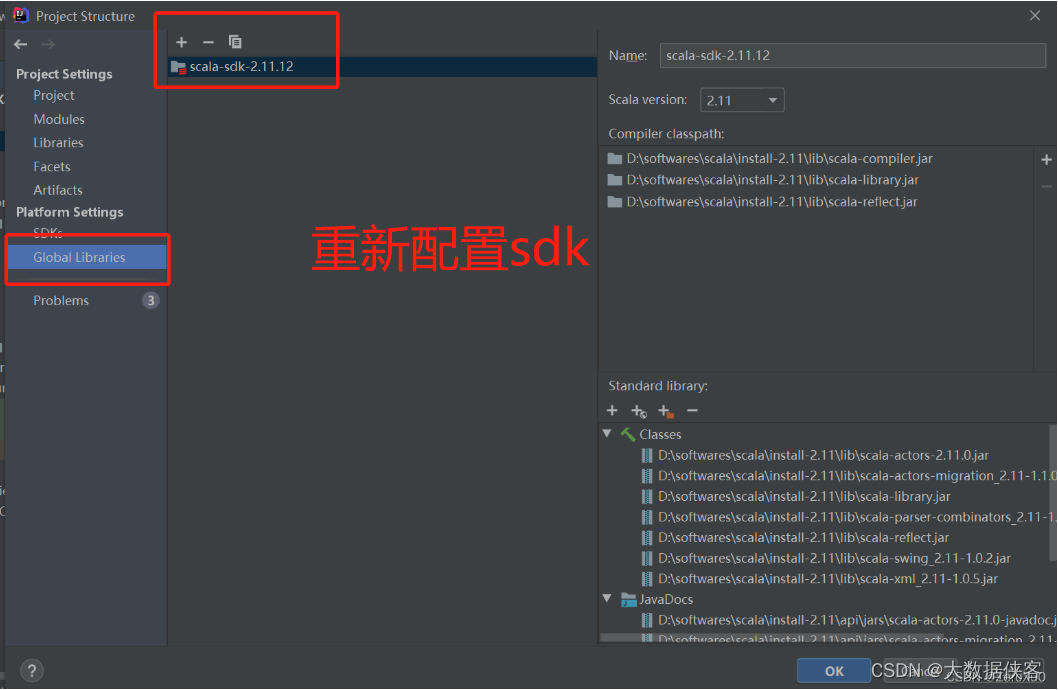
总结了下原因: 是idea自身的原因,设置好sdk后,idea卡住了,没有刷新sdk环境,就算关掉并重新打开idea也不行。其实还可以尝试下设置好sdk之后,重启下电脑,看是否能解决这个问题。3.把settings下maven的Use plugin registry选项勾选上。1.在global labrari重新配置sdk;2.1 新建file,以".scala"结尾。2.2 根据提示设置sca
git branch --set-upstream-to orgin/新分支名称。git puth --delete origin 自己的原分支名称。git branch -m 原分支名称 新分支名称。git push origin 新分支名称。4.修改后的本地分支与远程分支关联。1.重命名自己本地的分支。2.删除远程自己的原分支。3.推送新命名的分支。

如果已经使用了MongoDB的分片集群,可以通过创建一个新的分片集群,并将旧集群中的数据逐步迁移到新集群中来进行数据迁移。这可以通过将旧集群中的一个分片的数据迁移到新集群中的一个分片,然后逐步迁移其他分片的数据来实现。首先,在新的复制集中添加一个新的节点,然后将旧复制集中的数据复制到新的节点上。mongodump到具体查询条件,mongodump database1 的database1col表中

例如语句GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge),校验OVER子句时需要校验所有的 Edge type,如果 Edge type 包含 like和serve,该语句会展开为GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(ed
需要对score进行1-N排名,需要用到rank() ovre(业务逻辑)函数,但是又因为相同分数的学生,这样在相同排名的下一位学生只需要在之前相同排名的基础上+1即可,故要用到dense_rank() over(业务逻辑)函数。rank() over()与dense_rank() over()的作用基本相同,都是对查出指定条件后的进行排名,条件相同排名相同,排名间断不连续,区别在于dense_r
1、xml文件中编码为encoding=“UTF-8”,如其中有中文乱码,需要先调整正常显示,可以用sublime编辑器或者其他编辑器打开,把编码先修改成GB2312保存后,再修改成UTF-8即可;开发过程中也许需要对大批量数据进行对比查找,或者查找重复值,xml格式数据比较难定位到,但是利用excel可以处理过滤筛选。2、xml格式文件必须只能有一个根节点,如没有可以自行添加,拖入excel时如

用户名:***密码:***

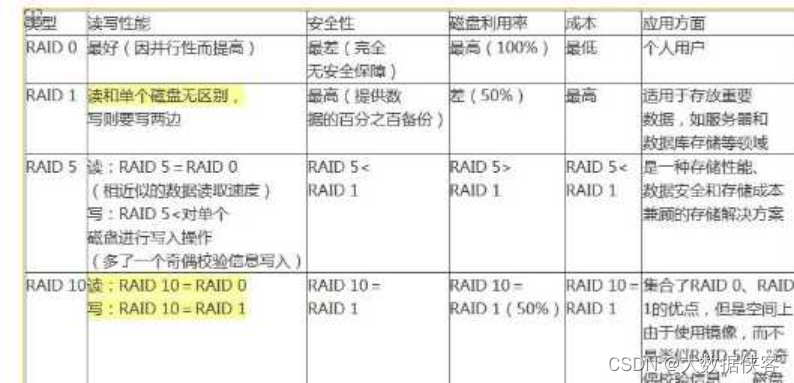
例如,总共有N块磁盘,那么会将要写入的数据分成N份,并发的写入到N块磁盘中,同时还将数据的校验码信息也写入到这N块磁盘中(数据与对应的校验码信息必须得分开存储在不同的磁盘上)。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别的写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有50%了,两块磁盘当做一块用,这是一种比较昂贵的方案。当我们要写数据的时候,会将数据分为N份,以独立