- @weixin_37990186
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
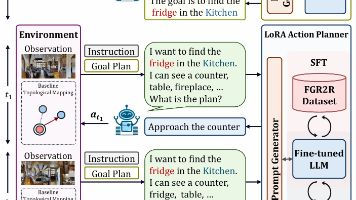
提出了参数高效的动作规划器PEAP-LLM,使智能体能够在每个位置与LLM交互以获得单步指令,从而提高导航效率!
论文提出的ARIO标准和新数据集显著改善了具身AI数据集的不足,提供了更丰富、更多样化和更大规模的数据。通过提供统一的数据格式和标准化的数据处理流程,ARIO为开发更强大、更通用的具身AI智能体铺平了道路。
具身智能多传感器融合感知在具身AI中具有重要的作用,通过整合多种传感器数据,可以显著提高系统的感知能力和决策准确性!

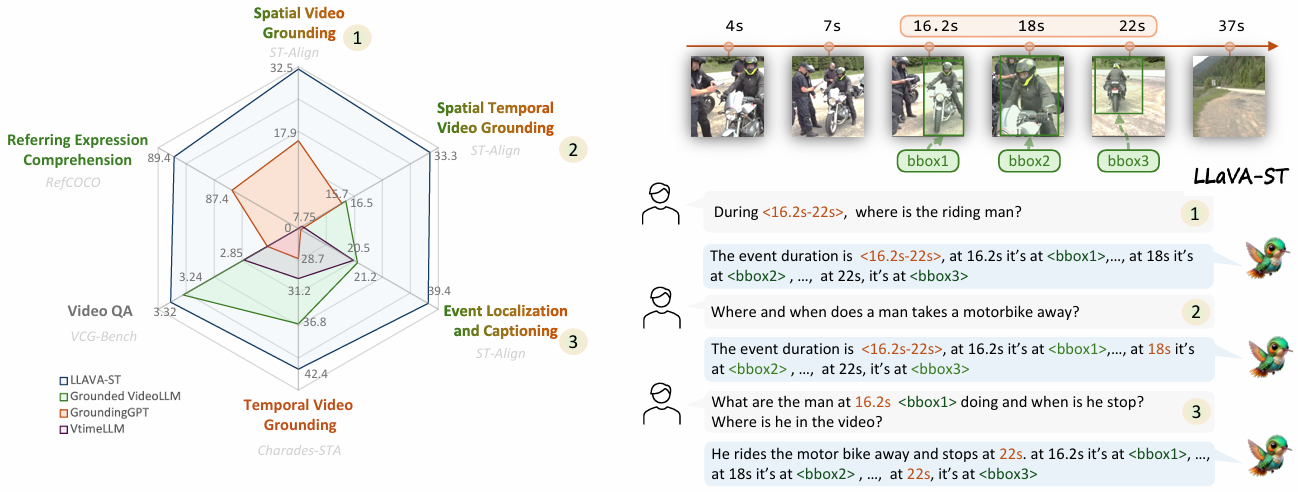
论文提出的LLaVA-ST是首个能够端到端处理细粒度时空多模态理解任务的MLLM。通过引入LAPE和STP模块,LLaVA-ST显著提高了模型在多个基准测试中的性能。实验结果表明,LLaVA-ST在处理时空交错任务时具有显著优势,并且在开放式视频问答和多选题视频问答任务中也表现出色。LLaVA-ST的提出为未来的MLLMs在细粒度多模态理解任务上的改进提供了重要的参考。
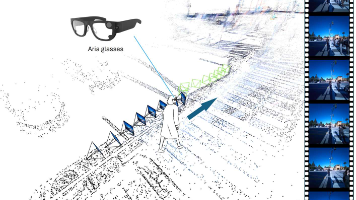
论文提出了LookOut模型,用于从第一人称视角视频预测未来6D头部姿态轨迹,以实现人形机器人在真实世界中的无碰撞导航,并贡献了相应的数据收集流程和数据集,通过实验验证了模型的有效性和泛化能力!
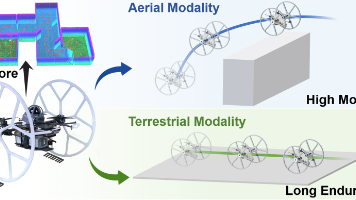
论文提出陆地-空中双模态车辆(TABV)的自主探索系统,通过分层框架和改进的双模态蒙特卡洛树搜索(BM-MCTS)方法,在给定的能量和时间预算下,灵活切换模态以最大化信息增益!
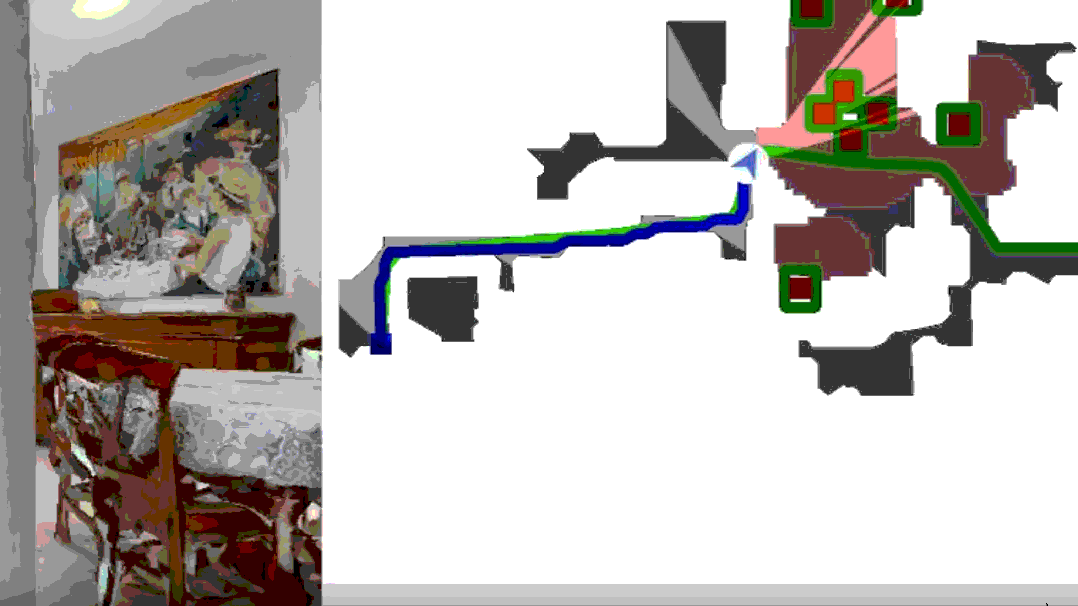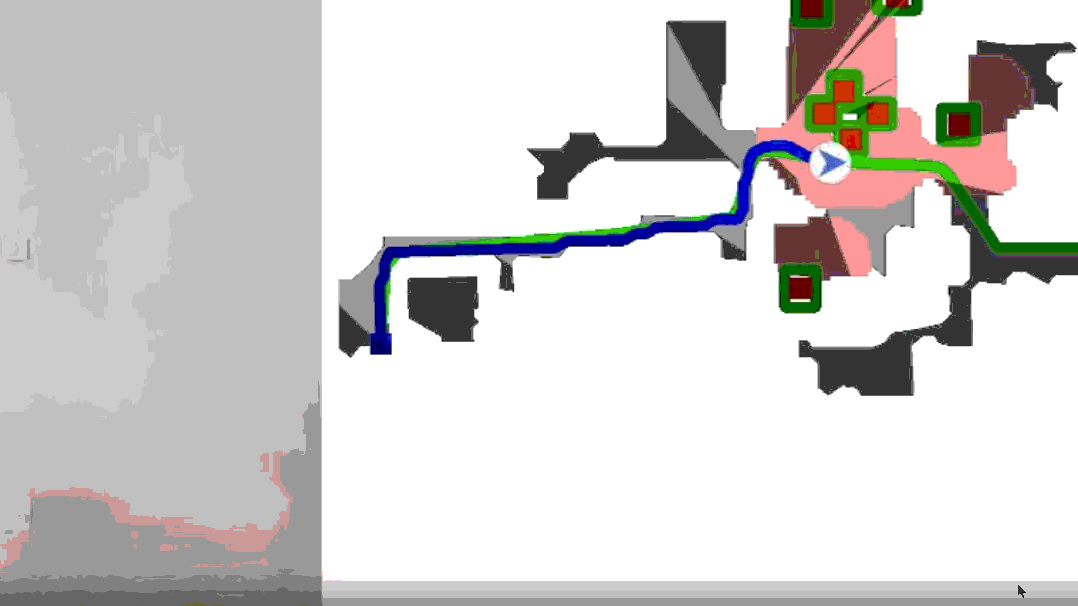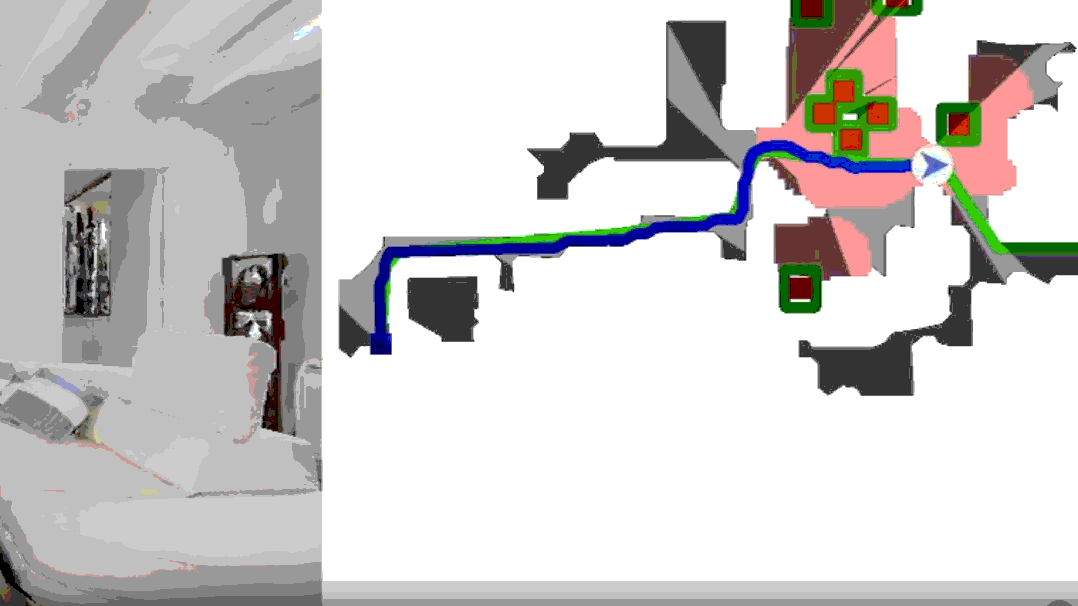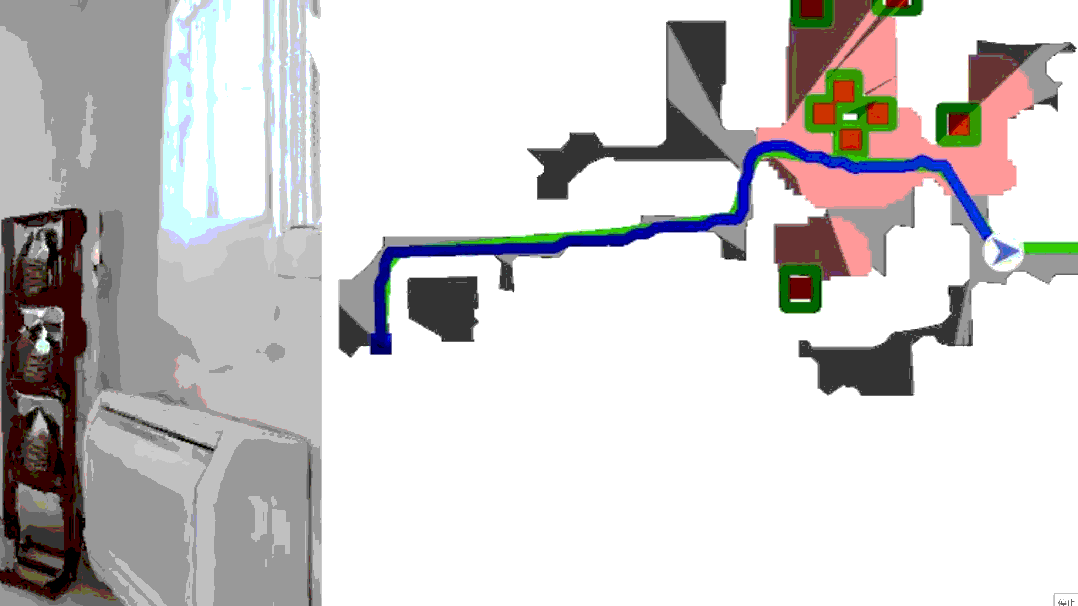
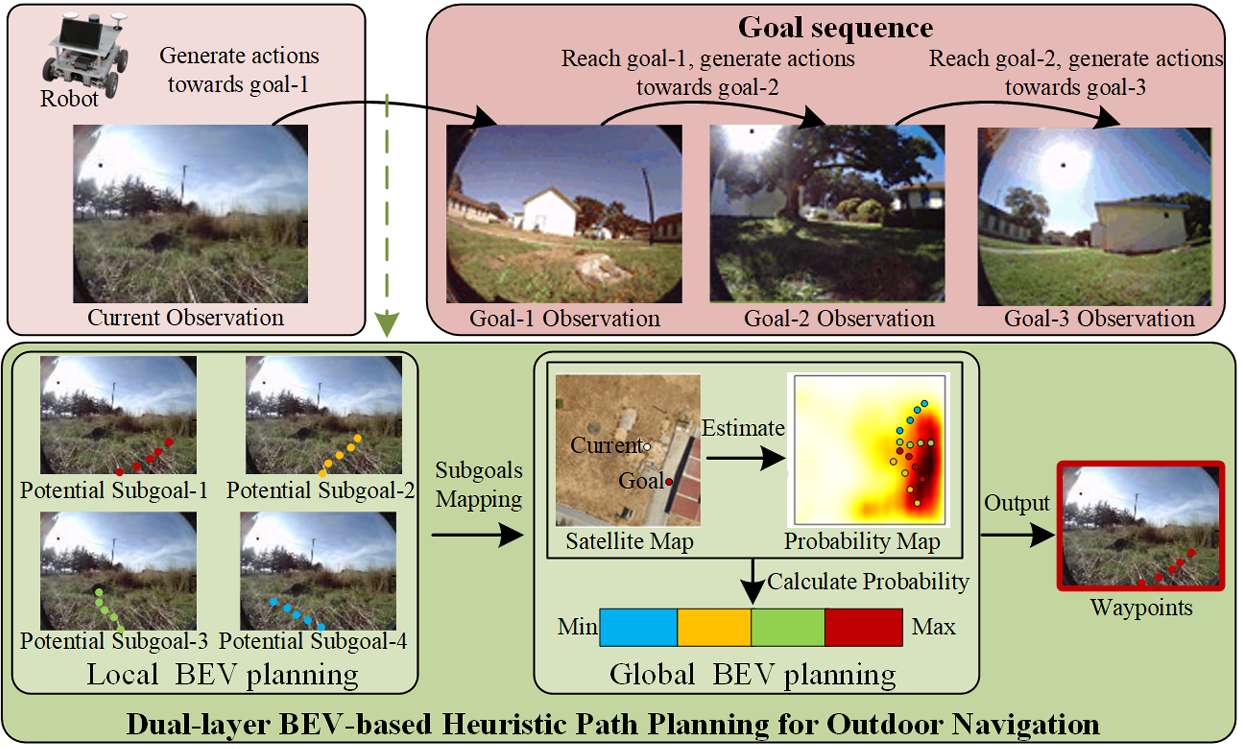
论文提出了一种结合局部和全局BEV规划的方法,从overhead地图中提取的全局BEV提示和实时局部BEV表示。增强了机器人在复杂户外环境中识别可通行性的能力,提高了路径规划的距离。未来的工作将计划结合无人机获取实时俯视视图,以进一步提升系统的鲁棒性和实时性能。
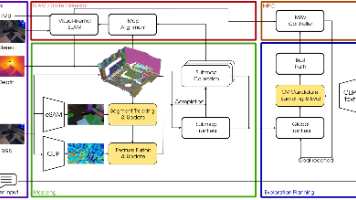
论文提出实时开放词汇对象中心的映射和探索框架FindAnything ,能够利用基础模型实现开放词汇引导的机器人探索!
论文提出了OmniVLA模型,通过融合多种模态(2D姿态、自身中心图像和自然语言)的目标条件进行训练,实现了强大的泛化能力和鲁棒性,为机器人视觉导航提供了一个灵活且可扩展的基础模型!

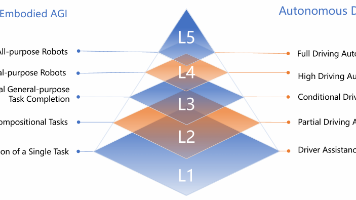
论文提出具身AGI的五级分类体系(L1-L5):从仅能完成单一任务的初级阶段(L1)到能够独立完成开放式任务且行为类似人类的高级阶段(L5),为具身AI的发展提供了明确的里程碑!