




- @weixin_32265569
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因mac自带python2.7环境,平时用的比较多的是python3.7,下面将安装及配置过程分享给大家,避免这些坑。1、安装软件包python3.7.pkg2、进入终端,配置Python3环境变量(1)open ~/.bash_profile# Setting PATH for Python 3.8PATH="/Library/Frameworks/Python.framework/Versio
DeepSeek连续多日引发了全民关注,服务器还一度卡到宕机。采用压缩数据量、并行提效、蒸馏技术,得到更为精炼、有用的数据。一度让英伟达股价暴跌17%!

Python介绍Python是一种计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型的项目的开发。Python是一种解释型脚本语言,可以应用于以下领域:Web和Internet开发科学计算和统计教育桌面界面开发软件开发后端开发Python的安装Python下载链接:https://www.p
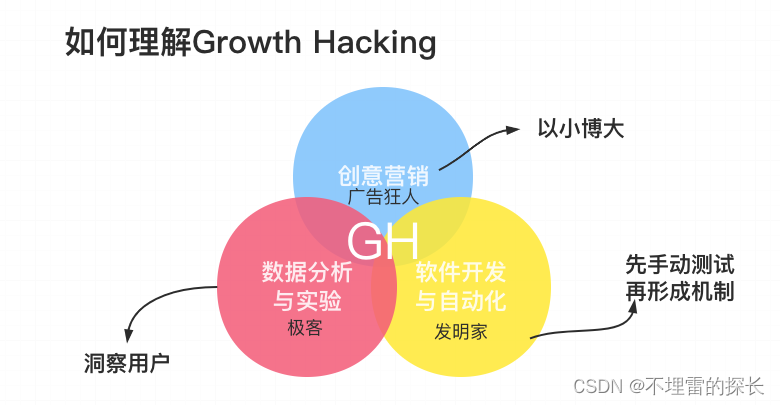
帮助互联网创业公司搭建从0到1的指标体系建设,重点关注第一关键指标(One Metric)、AARRR(海盗)模型;根据自身产品的MVP阶段、增长阶段、变现阶段的划分以及数据的大、全、细、时特点,利用代码埋点、可视化埋点、无埋点等方式进行全部数据源采集,方便后续的多维数据建模及数据分析。
Flink_思维导图(干货).xmind.zip算法思维导图【全面】.xmind.zipSpark 机器学习.xmind.zipJava集合思维导图.xmind.zipTCP&SOCKET&三次握手全解.xmind.zipMySQL_思维导图(全面).xmind.zip文章最后,给大家推荐一些受欢迎的技术博客链接:JAVA相关的深度技术博客链接Flink 相关技术博客链接Spark
本文将围绕 AI发展、智能体构建、增效搭子 三大核心视角,深入探索人与AI协同提效的未来路径。我们将审视AI技术本身从“感知”走向“行动”与“创造”的演进,剖析如何系统性地构建高质量的数据基石以赋能AI,并最终聚焦于“增效搭子”这一人机协作的新范式——它不再是简单的工具替代,而是深度融合、相互增强的智能伙伴。
本文将围绕 AI发展、智能体构建、增效搭子 三大核心视角,深入探索人与AI协同提效的未来路径。我们将审视AI技术本身从“感知”走向“行动”与“创造”的演进,剖析如何系统性地构建高质量的数据基石以赋能AI,并最终聚焦于“增效搭子”这一人机协作的新范式——它不再是简单的工具替代,而是深度融合、相互增强的智能伙伴。
本文将围绕 AI发展、智能体构建、增效搭子 三大核心视角,深入探索人与AI协同提效的未来路径。我们将审视AI技术本身从“感知”走向“行动”与“创造”的演进,剖析如何系统性地构建高质量的数据基石以赋能AI,并最终聚焦于“增效搭子”这一人机协作的新范式——它不再是简单的工具替代,而是深度融合、相互增强的智能伙伴。
先需要下载好 arthas工具:官网链接https://github.com/alibaba/arthas/blob/master/README_CN.md下载方式:curl -O https://arthas.aliyun.com/arthas-boot.jar运行 arthas:java -jar arthas-boot.jar阿里开源 arthas 帮助命令一览表命令命令描述中文描述help
先来看下词云效果图吧!实现词云图2种方式word_cloud、stylecloudword_cloud :http://amueller.github.io/word_cloud/stylecloud :https://github.com/minimaxir/stylecloud1、需要先添加一下maven依赖<dependency><groupId>com.kennyc