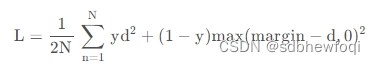- @weixin_31866177
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关于数据集的划分是基本概念,但是有时候看其他人代码时,经常被弄得云里雾里。特作此记录。
RMSE(均方根误差)、MSE(均方误差)、MAE(平均绝对误差)、SD(标准差)RMSE(Root Mean Square Error)均方根误差衡量观测值与真实值之间的偏差。常用来作为机器学习模型预测结果衡量的标准。MSE(Mean Square Error)均方误差MSE是真实值与预测值的差值的平方然后求和平均。通过平方的形式便于求导,所以常被用作线性回归的损失函数。...
回顾以下word2vec,负采样的思想更加直观:为了解决数量太过庞大的输出向量的更新问题(word2vec这里要预测是哪个单词,而单词库上万),我们就不更新全部向量,而只更新他们的一个样本。显然正确的输出单词(也就是正样本)应该出现在我们的样本中,另外,我们需要采集几个单词作为负样本(因此该技术被称为“负采样”)。采样的过程需要指定总体的概率分布,我们可以任意选择一个分布。我们把这个分布叫做噪声分
id类特征类别型特征
训练过程中发现,train loss一直下降,train acc一直上升;但是val loss、val acc却一直震荡。loss一会上一会下,但是总体趋势是向下的。“loss震荡但验证集准确率总体下降” 如何解决?
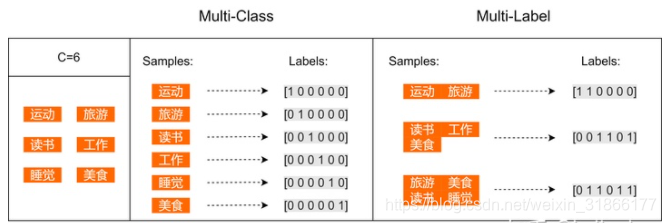
1、Multi-Class:多分类/多元分类(二分类、三分类、多分类等)二分类:判断邮件属于哪个类别,垃圾或者非垃圾二分类:判断新闻属于哪个类别,机器写的或者人写的三分类:判断文本情感属于{正面,中立,负面}中的哪一类多分类:判断新闻属于哪个类别,如财经、体育、娱乐等2、Multi-Label:多标签分类文本可能同时涉及任何宗教,政治,金融或教育,也可能不属于任何一种。电影可以根据其摘要内容分为动
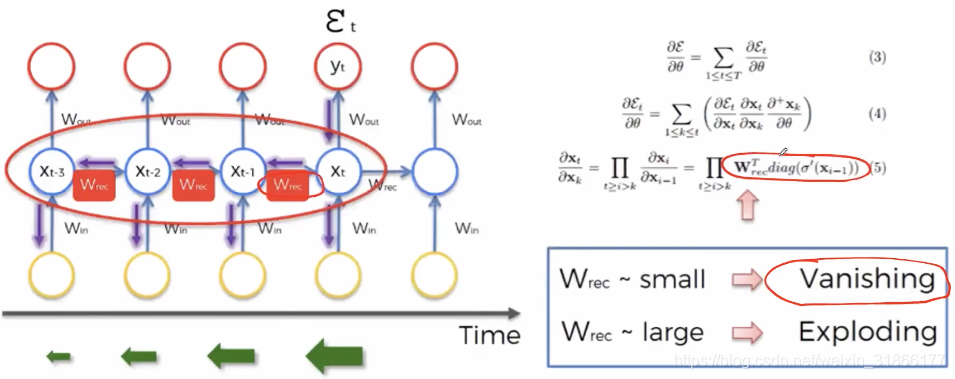
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.在机器翻译的任务中,使用RNN会造成梯度消失和长句子传递信息缺失的问题。LSTM只能缓解,如果想要进一步提升,就引入了Transformer。这里的新思想是不用RNN来做机器翻译。...
这次记录里说明了如何计算视频播放时长【计算机视觉】ffmpeg获取视频详细信息含视频时长在linux环境下,出现报错 ffprobe not found, 尽管已经安装了pip ffmpeg,但是显然环境并没有知道已经安装了。解决办法参考https://stackoverflow.com/questions/30770155/ffprobe-or-avprobe-not-found-please-
目录1、计算视频总帧数2、视频中的 FPS,即:每秒传输帧数(Frames Per Second))3、视频按帧保存成图片4、按帧合成视频5、视频按照 指定时间/ 指定帧率 保存成图片1、计算视频总帧数ffmpeg$ffmpeg -i test.avi -vcodec copy -f rawvideo -y /dev/null 2>&1 | tr ^M '\n' | awk '/^f
自己总结一下,三元组如果正负样本足够开,距离足够远,loss为0,因为模型已经学的不错了,不需要继续学习。最好的负样本是,model预测负样本的把握不太大的。如果负样本是很难分的,例如d(a,p)>=d(a,n),即负样本和anchor离的更近,loss是最大的,但模型不容易学出来。并且三元组loss每次只对一条样本(a,p,n)进行loss计算,不考虑其他的负样本。CLIP则是batch_siz