




- @wangyifan123456zz
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第11章,并行模式:合并排序,介绍合并排序,以及动态输入数据识别和组织。然后,它涵盖了涉及的思维过程:(1)识别要并行化的应用程序部分,(2)隔离并行化代码使用的数据,使用APl函数在并行计算设备上分配内存,(3)使用APl函数将数据传输到并行计算设备,(4)开发将由并行化部分线程执行的内核函数,(5)启动并行线程执行的内核函数,以及(6)最终通过APl函数调用将数据传输回主机处理器。第20章,关
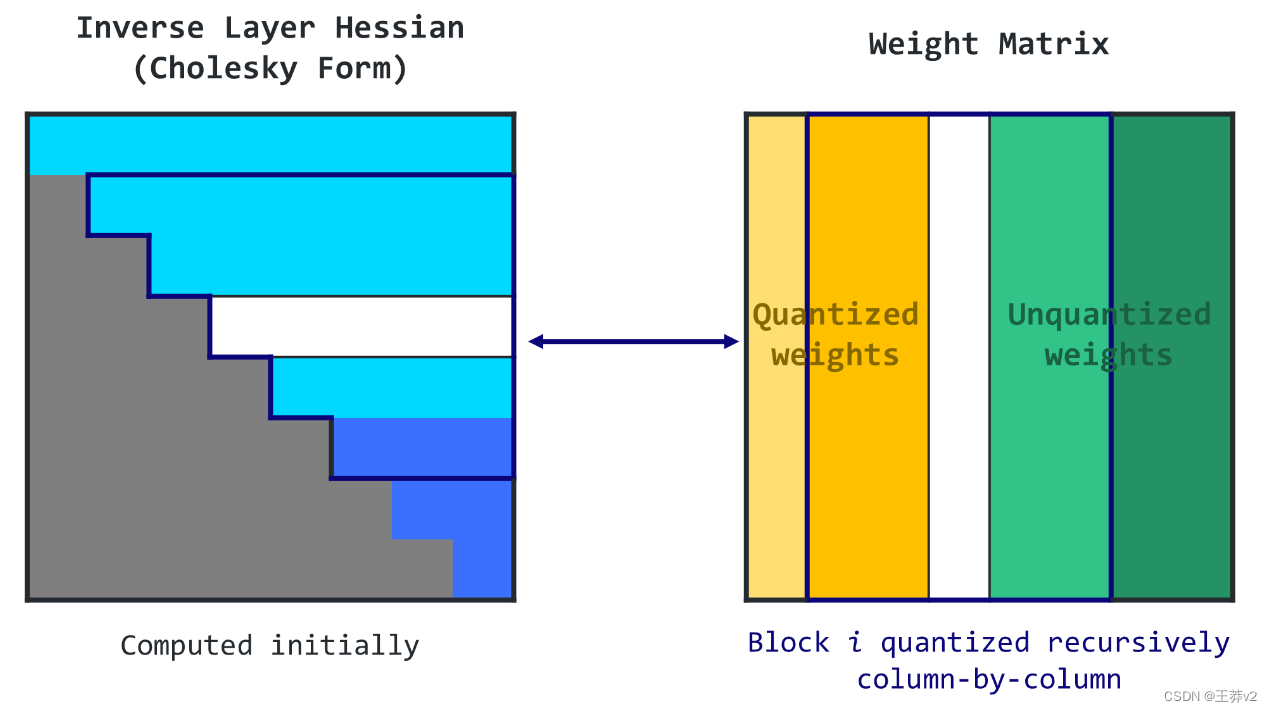
当一些权重被中间更新推到网格之外时,这种效果可能会恶化。一个简单的启发式应用来防止这种情况:异常值一出现就被量化。这个过程可能需要大量的计算,特别是对于LLMs。为了解决这个问题,OBQ方法使用了一种技巧,避免在每次简化权重时重新进行整个计算。量化权重后,它通过删除与该权重相关的行和列(使用高斯消去)来调整计算中使用的矩阵(Hessian矩阵)。该方法还采用向量化的方法,一次处理多行权矩阵。尽管O
如果想要使用vscoed编辑docker中的代码,先启动容器docker exec -it $(docker container ls -q) /bin/bash然后启动vscodecode --user-data-dir此时vscode在docker的目录下打开,左上角打开想要编辑的文件就行了。
罗斯等人[2011]提出了一种名为DAGGER的元算法,该算法试图在学习策略诱导的状态分布下收集专家演示。模仿学习的策略方法[萨顿和巴托,1998]:专家提供正确的行动,但例子的输入分布来自学习者自己的行为。图显示了DAGGER模仿学习方法的概述。 最简单的DAGGER形式如下。 在第一次迭代时,策略通过专家演示的行为克隆初始化,导致策略π1Lπ_1^Lπ1L。 随后,该策略被用来收集轨迹数据集
摘要继AlphaGO系列的显著成功之后,2019年是蓬勃发展的一年,见证了多智能体强化学习(MARL)技术的显著进步。MARL对应于多智能体同时学习的多智能体系统中的学习问题。它是一个具有悠久历史的跨学科领域,包括博弈论、机器学习、随机控制、心理学和优化。虽然MARL在解决现实世界的游戏方面取得了相当大的经验成功,但文献中缺乏一个独立的概述来概述现代MARL方法的博弈理论基础,并总结了最新的进展。