




- @wangwangstone
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录tf.data.TFRecordDataset含义Dataset函数解析tf.data.Dataset.batch 、map、shuffle、repeattf.data.Dataset.make_one_shot_iterator().get_next()一个几乎通用tfrecord 的数据解析函数tf.data.TFRecordDataset含义Class TFRecordDataset。A
指定缺失值的填充值利用pd.read_csv读取文件加载时,默认会将文件中缺失的数据自动填充为NaN,如果想指定缺失数据的填充值,则可以利用里面的na_values参数。import pandas as pddata=pd.read_csv("./selectRefer10PerClass0317.txt",sep='\t')data.head()此时对于对于缺失数据的填充值为Nan指定以某个值去
含义:(1)iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数;(2)batch-size:1次迭代所使用的样本量;(3)epoch:1个epoch表示过了1遍训练集中的所有样本。值得注意的是,在深度学习领域中,常用带mini-batch的随机梯度下降算法(Stochastic Gradient Descent, SGD)训练深层结构,它有一个好处就
torch.rand和torch.randn有什么区别? y = torch.rand(5,3) y=torch.randn(5,3)一个均匀分布,一个是标准正态分布。均匀分布torch.rand(*sizes, out=None)→ Tensor返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。参数:sizes (int...
最终差强人意的解决方案:方案1:在QQ浏览器或者chrome中,先将目标网页,从头拉到底后(不能太快)本地浏览器将目标网页渲染完成后,再讲鼠标拉倒网页最上方初始位置处。再右击,选择打印。(QQ浏览器的效果会好些)下拉窗口,选择目标打印机,也可以先保存为本地pdf。双面打印。其他设置如下:有时候浏览器渲染不稳定,先看打印预览。不行,打印(打印预览后),浏览器中上下拉动...
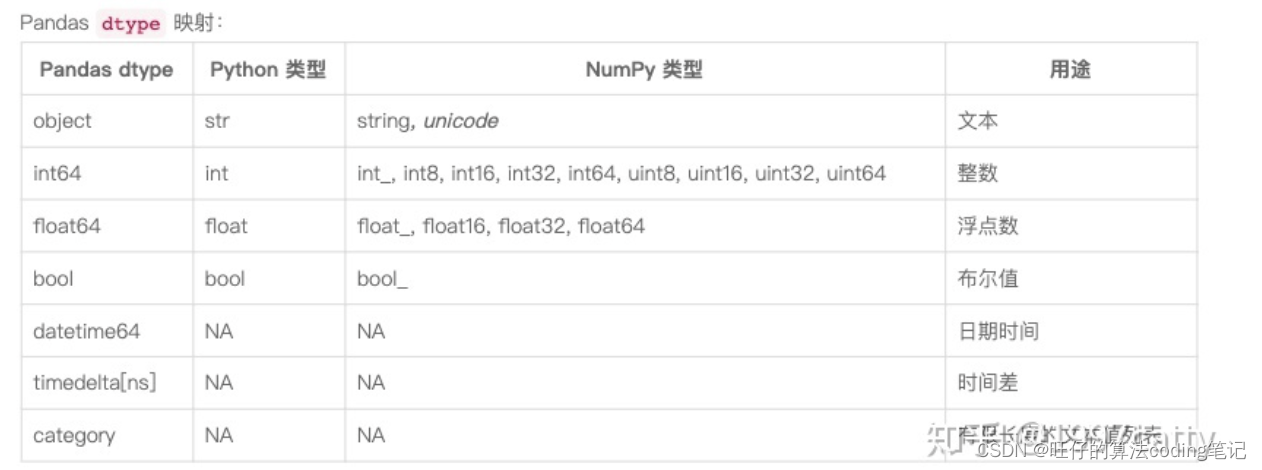
pandas中查看各列数据类型的函数为 df.dtypes , 注意后面不用加括号。 pandas中各数据类型与python的对应关系表如下: 注意python中的字符串str类型默认是对应object,但是object并不完全具有str的特性,因此如果想要用str的特性,一般最好是是强制转换为str而不是设置为object类型。 (因为object在pandas中通常是不能全部转换为int或者f
执行脚本时,常需要设置自动执行的时间,就不用定闹铃半夜起床去启动脚本了,更充分的利用服务器。需要处理的数据,将date作为变量传进for循环里,去自动处理脚本数据。最基本的格式date +"%Y%m%d"输出当前日期。 注意上面是Y (下面会讲)20200904date命令作用:是显示或设置系统时间与日期。语法date(选项)(参数)选项-d<字符串>:显示字符串所指的日期与时间。字符
from_unixtimefrom_unixtimehive sql 中时间戳转换函数: 由bigint类型的值转换为指定时间戳格式; from_unixtime()from_unixtimefrom_unixtime(bigint unixtime[, string format])返回值类型:string功能: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒
lstm里,多层之间传递的是输出ht ,同一层内传递的细胞状态(即隐层状态)看pytorch官网对应的参数nn.lstm(*args,**kwargs),默认传参就是官网文档的列出的列表传过去。对于后面有默认值(官网在参数解释第一句就有if啥的,一般传参就要带赋值号了。)官网案例对应的就是前三个。input_size,hidden_size,num_layersParmerters...
在查看VMware中,设置成了NAT 模式后,(“虚拟机”->“虚拟机设置”—>“网络适配器”->选择NAT )NAT(network addresstransform)是共享主机的ip地址,来上网,在centos7里,点击“系统工具”—>“设置”--->“网络”选择“有线”,将手动改为自动。 需要核对位置。.