- @vipdafei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
很多刚接触时序与时空预测领域的朋友,常常会陷入两个极端:要么一上来就硬啃复杂的 SOTA 模型,连基础算子都没搞懂就想复现顶会成果,最后处处碰壁;要么只停留在基础概念的背诵,没法把知识落地到实际的预测任务中。其实,想要高效入门这个领域,和盖一栋楼的逻辑完全相通 —— 先打牢地基,再搭主体框架,接着填充功能模块,最后做优化迭代,一步一步稳扎稳打,才能真正建立起完整的知识体系。今天就把我亲测有效的入门

《高效撰写毕业论文/学术论文全流程指南》为科研新手提供了一套实用方法论。文章围绕"选题-创新-实验-写作"四个关键环节展开:选题应优先考虑可用数据而非热门领域;创新点可通过模块微调而非颠覆性改革实现;实验需先跑通基础模型再优化;写作要遵循结构化框架,从摘要倒推全文。指南强调科研是流程化工作而非天才式突破,推荐了Paper with Code等实用工具,帮助读者避开90%的科研弯
本文介绍了如何通过open-webui在本地部署Qwen3-14B大模型的Web界面。主要步骤包括:创建Python3.11的conda环境,一键安装open-webui,配置vLLM模型API接口的环境变量,启动服务后通过浏览器访问8080端口进行注册和使用。重点提示需将OPENAI_API_BASE_URL指向本地模型服务地址(如127.0.0.1:8000/v1),并设置HF_HUB_OFF
本文详细介绍了Qwen3-14B大模型基于vLLM框架的部署方案,包含INT8量化和API服务搭建。部署要求:48GB显存显卡(如RTX 6000 Ada)、32GB内存、50GB存储空间,推荐Ubuntu 24.04系统。核心步骤包括:1)创建conda环境并安装Python 3.10、PyTorch 2.1.0+cu120等基础依赖;2)配置vLLM 0.14.1、bitsandbytes 0
本文详细介绍了Qwen3-14B大模型基于vLLM框架的部署方案,包含INT8量化和API服务搭建。部署要求:48GB显存显卡(如RTX 6000 Ada)、32GB内存、50GB存储空间,推荐Ubuntu 24.04系统。核心步骤包括:1)创建conda环境并安装Python 3.10、PyTorch 2.1.0+cu120等基础依赖;2)配置vLLM 0.14.1、bitsandbytes 0
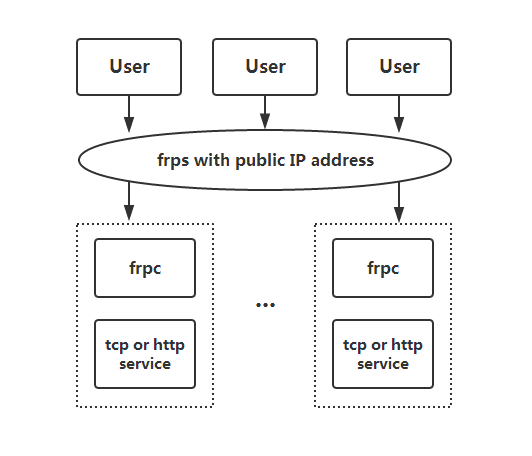
frp的详细部署流程,快来一起内网穿透吧!