




- @unamable
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
视觉 Transformer 优秀开源工作:timm 库 vision transformer 代码解读 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/3508372791 什么是 timm 库?PyTorchImageModels,简称 timm,是一个巨大的PyTorch代码集合,包括了一系列:image modelslayersutilitieso
一、motivation二、solution
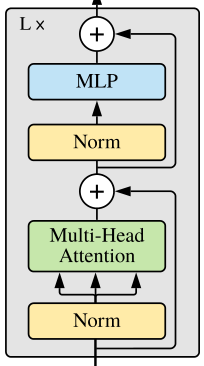
一、Transformer结构图二、分部分计算FLOPs1.Encoder(1)input_embedingInput假设是一个维度为vocab的向量,通过Input_embeding部分变成 vocab*d_model的矩阵:即(vocab*1)@(1*d_model)=vocab*d_model次乘法。再乘上d_model ** 0.5 所以 Input_embeding的FLOPs = vo

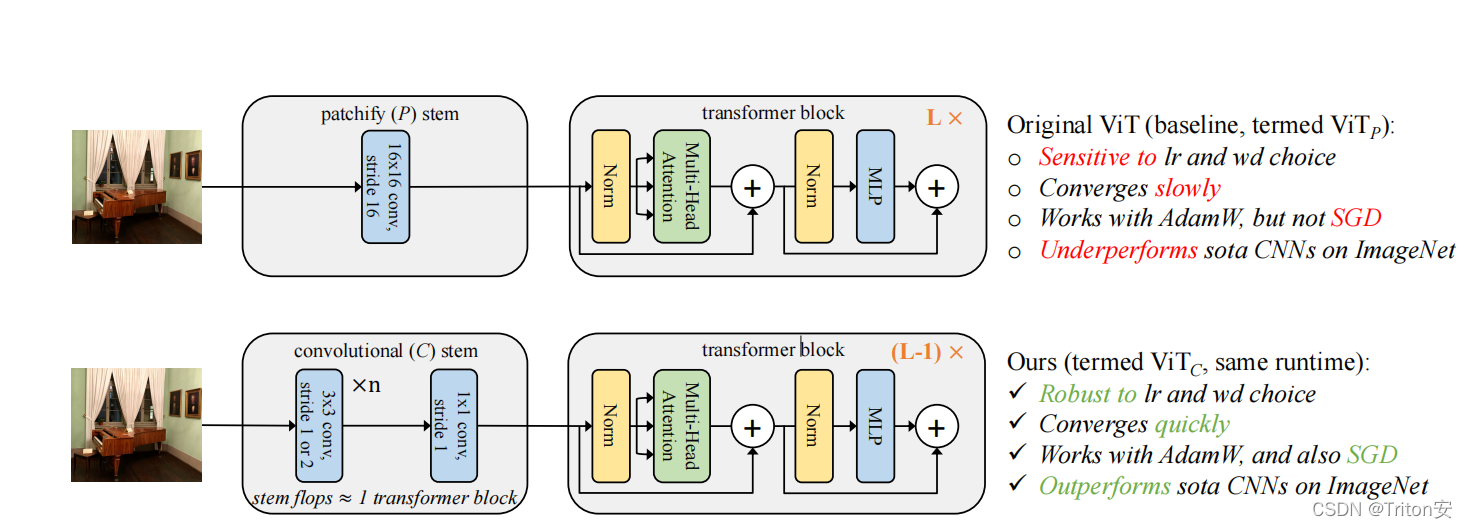
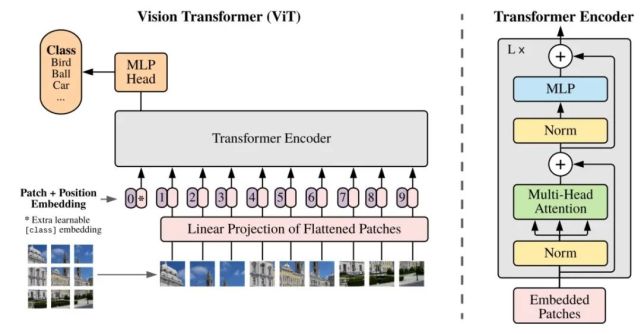
一、背景1.Transformer 架构早已在自然语言处理任务中得到广泛应用2.在计算机视觉领域,注意力要么与卷积网络结合使用,要么用来代替卷积网络的某些组件,同时保持其整体架构不变。3.基于自注意力的架构,尤其 Transformer,已经成为 NLP 领域的首选模型。该主流方法基于大型文本语料库进行预训练,然后针对较小的任务特定数据集进行微调。由于 Transformer 的计算效率和可扩展性
同期论文如Swin Transformer和Pyramid Vision Transformer都很不错!不过这里只简单介绍CAT。提出了一种新的注意力机制,称为Cross Attention,它在图像块内而不是整个图像中交替注意以捕获局部信息,并结合Transformer构建为CAT,表现SOTA。性能优于PVT、CrossViT等网络。对图像进行Tokenization之后,用图像块替换Tra
