




- @u013810234
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文通过组合 Dify 的工作流编排、 Tavily Search 搜索引擎工具以及 Qwen2.5 模型,成功实现了一个能够回答实时问题的 AI 搜索引擎,步骤详细,极具可操作性。后续想办法解决模型对相对时间(今天、昨天、去年等)的理解存在局限性。这个 AI 搜索引擎能够回答一些实时新闻和事件相关的问题,展示了 Dify 工作流编排功能的便捷性、实用性。

本文通过使用Dify平台的工作流编排功能,结合阿里百炼的大型语言模型(如qwen2.5-14b-instruct等),成功打造了一个专属的AI数据分析师。能够根据用户提供的自然语言问题生成对应的SQL查询语句,并通过部署好的API服务执行这些查询,最终由另一个LLM节点对查询结果进行专业的数据分析和可视化展示。可以统计创作唐诗最多的作者、分析唐诗中特定元素的出现频率,以及联合查询作者信息与作品数量

想将一个线上数据库从 SQLServer 转换迁移到 MySQL ,数据表70多张,数据量不大。从网上看很多推荐使用 SQLyog ,还有 Oracle MySQL Server 官方的 Workbeach 来做迁移,但是步骤稍显繁琐;后来从一篇文章的某个角落中发现了 DB2DB 这个工具,出自于米软科技。从软件功能上看,当前版本 1.30.107 支持 SQLServer , MySQL , S
你是不是也有私有化部署大模型的需求?如今有了Ollama,HuggingFace,ModelScope等开源平台,我们可以非常方便地搭建一个属于自己的大模型,如果网速给力,真是分分钟~~。简单起见,这篇文章仅用到了Ollama官方提供的一个2G大小的模型:llama3.2(3B),后续还可以私有化部署通义千问(Qwen)、智谱AI(glm)等知名大模型。在一台纯CPU的虚拟机上部署Ollama与O

本文介绍了开源商业智能工具Metabase的技术特点及其在古诗词数据库分析中的应用。Metabase采用Clojure+Java技术栈,支持多数据源查询与可视化,降低了数据分析门槛。文章展示了基于唐诗宋词数据库(包含诗歌、作者、诗经等5张表)构建的Dashboard效果图,并详细列出了各表结构(如poetry表含id、title、content等字段)。通过该案例,体现了Metabase在非结构化
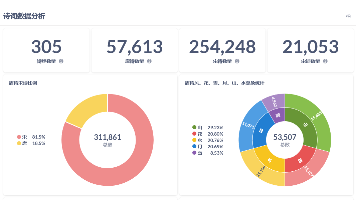
本文介绍了开源商业智能工具Metabase的技术特点及其在古诗词数据库分析中的应用。Metabase采用Clojure+Java技术栈,支持多数据源查询与可视化,降低了数据分析门槛。文章展示了基于唐诗宋词数据库(包含诗歌、作者、诗经等5张表)构建的Dashboard效果图,并详细列出了各表结构(如poetry表含id、title、content等字段)。通过该案例,体现了Metabase在非结构化
本文记录了在Docker环境下通过Prometheus和Grafana实现对MinIO服务的监控。具体步骤包括在服务节点上使用mc生成抓取配置,配置Prometheus抓取MinIO的监控数据,并在Grafana中配置数据源和导入现成的监控仪表板,以实现对分布式对象存储服务的性能监控和可视化。

没有度量就没有改进,实际上,监控系统有以下两个客户:技术,业务。上述内容即是对技术组件的监控,方便技术方面的改进与优化。本文记录了在Docker环境下通过Prometheus和Grafana实现对MySQL和Redis服务的监控。具体步骤包括在服务节点上使用docker-compose安装mysqld-exporter和redis_exporter,配置Prometheus抓取MySQL和Redi

HAAS510 是一种开板式 DTU ,旨在为用户已开发好的设备快速增加 4G 连云能力的 4G CAT1 数传模块。它通过将模组与用户设备集成到一个外壳内,既保持设备的一体性,又降低重新开发 PCB 的时间消耗和模组开发的难度。 HAAS510 产品采用了 JavaScript 脚本的方式,将模组的本地串口通信和通过 4G 连接云端平台的能力开放给用户。依托阿里云物联网平台,结合 HAAS510

本文通过使用Dify平台的工作流编排功能,结合阿里百炼的大型语言模型(如qwen2.5-14b-instruct等),成功打造了一个专属的AI数据分析师。能够根据用户提供的自然语言问题生成对应的SQL查询语句,并通过部署好的API服务执行这些查询,最终由另一个LLM节点对查询结果进行专业的数据分析和可视化展示。可以统计创作唐诗最多的作者、分析唐诗中特定元素的出现频率,以及联合查询作者信息与作品数量