




- @u012599545
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
入库:5000个文档原样入库,附带丰富的 Metadata。检索:用户提问 -> 同时进行BM25(抓关键字命中) 与Vector(抓语义相似) -> 合并候选集。重排:候选集送入轻量级 Cross-Encoder Reranker 进行精排。生成:Top 5 结果交给大模型生成最终答案。这套方案完全避开了重型框架的臃肿,专门针对短文本和元数据的特性进行了算法优化,在5000个文档的体量下,
Hindsight-Guided On-Policy Distillation (OPD) 是OpenClaw-RL中一种关键的训练方法,旨在从“下一状态信号”中提取指令性信息,并将其转化为的训练信号,以指导模型改进。传统的强化学习(RL)通常使用标量奖励(例如+1表示成功,-1表示失败),这种奖励虽然能评估操作好坏,但丢失了大量关于“如何改进”的细节信息。OPD的目标就是从下一状态信号中恢复这些
n:next,单步调试s: step info,进入函数d: down,深入函数层级u: up,返回上一层级ctrl +x:进入python当前上下文解释器模式,可输入查看变量,如len(total_queries),会打印8,再次执行ctrl +x 回到调试窗口q:可退出调试感觉挺方便Keys: # 快捷键相关Ctrl-p - edit preferences # 编辑配置n - step ov
(1)在configs/datasets目录下,新增search_instruction_non_pack.yaml文件(参考alpaca_instruction_non_pack.yaml),注意这里pack和nopack的区别,pack一般用于多轮,含有history等字段,非pack模式下,有instruction,input,output字段即可。修改模型目录,设置pp为1,执行:sh e
Hindsight-Guided On-Policy Distillation (OPD) 是OpenClaw-RL中一种关键的训练方法,旨在从“下一状态信号”中提取指令性信息,并将其转化为的训练信号,以指导模型改进。传统的强化学习(RL)通常使用标量奖励(例如+1表示成功,-1表示失败),这种奖励虽然能评估操作好坏,但丢失了大量关于“如何改进”的细节信息。OPD的目标就是从下一状态信号中恢复这些
这里的ToolMessage和Command来自:来自AI的回复,可能是一些text块。这里值得借鉴。
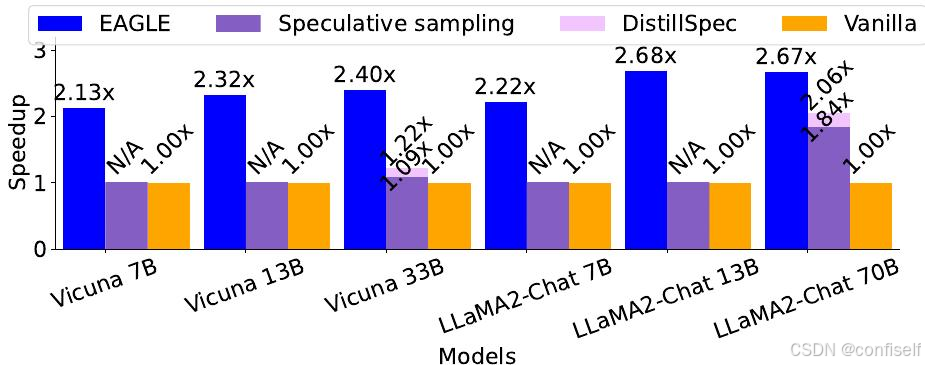
使用 Vicuna-68M 作为草稿模型的标准推测性采样也实现了显著的加速,但与其他方法相比,其训练开销要高得多。
使用的模型基座为:qq8933/OpenLongCoT-Base-Gemma2-2B,描述如下:This model is a fine-tuned version of google/gemma-2-2b-it on the OpenLongCoT dataset.This model can read and output o1-like LongCoT which targeting wor

信息抽取模型可直接使用大模型本身来抽取,也可以使用现有的信息抽取模型需要一个信息抽取模型需要评测基准验证该评估方法的可行性,并与人类对齐https://arxiv.org/pdf/1905.13322待定⌛️效果一般,且需要依赖较为复杂且可靠的信息抽取模型。例如,大型语言模型(LLMs)可以从生成性反馈循环中显著受益,通过Milvus这样的开源向量数据库,可以高效地存储和检索编码文本数据语义的向量

另外,seq2seq中decoder,attention的更新机制没有说清楚(其实就是梯度下降更新权重即可),若使用attention机制,则h0'没有说清楚(需要看下源码部分)(1)对于这里面RNN的表示中,使用了输入x和h的拼接描述,其他公式中也是如此。注意:这里补充了对于RNN,UVW三个矩阵的使用细节,很多喜欢使用下面这张图。(2)各符号图含义如下。
