




- @u010955999
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
知识抽取涉及的“知识”通常是 清楚的、事实性的信息,这些信息来自不同的来源和结构,而对不同数据源进行的知识抽取的方法各有不同,从结构化数据中获取知识用 D2R,其难点在于复杂表数据的处理,包括嵌套表、多列、外键关联等,从链接数据中获取知识用图映射,难点在于数据对齐,从半结构化数据中获取知识用包装器,难点在于 wrapper 的自动生成、更新和维护,这一篇主要讲从文本中获取知识,也就是我们广义上说的
Part 11. Spark计算模型1.1 Spark程序模型首先通过一个简单的实例了解Spark的程序模型。1)SparkContext中的textFile函数从HDFS读取日志文件,输出变量file。valfile=sc.textFile("hdfs://xxx")2)RDD中的filter函数过滤带“ERROR”的行,输出errors(errors也是一个RDD)。...
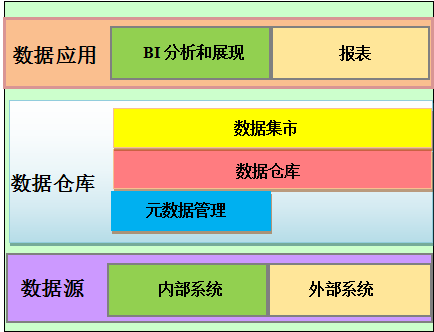
数据仓库数据仓库(Data Warehouse DW)是为了便于多维分析和多角度展现而将数据按特定的模式进行存储所建立起来的大型数据库,它的数据基于事务型的关系数据库。数据仓库中的数据是相对稳定的、集成的、面向主题的、反映历史变化的,以分析需求为目的数据集合。数据集市数据集市是数据仓库的一个逻辑子集。(1) 特定用户群体所需的信息,通常是一个部门或者一个特定组织的用户。(2) 访问相对稳定的业务信
centos安装使用的是CentOS-7-x86_64-DVD-1708.iso root登录ssh 设置开机自动联网配置linux环境更改openjdk为java jdk卸载openjdk安装java jdk安装python配置python环境变量安装Jupyter安装单机spark将pyspark与jupyter连接使用jupyter...
# !/usr/bin/env python# -*- encoding: utf-8 -*-# Created on 2018-07-06 12:30:04# Project: test1from pyspider.libs.base_handler import *class Handler(BaseHandler):crawl_config = {}...