- @u010848845
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、kafka本身2、外部存系统zookeeper、hbase、mysql、redis、hdfs等3、sparkstreaming的checkpoint参考:https://www.jianshu.com/p/ef3f15cf400d
入口配置阿里云镜像{"experimental": false,"features": {"buildkit": true},"registry-mirrors": ["https://3ksoxp7c.mirror.aliyuncs.com"]}参考:https://blog.csdn.net/qq_40168110/article/details/105972785
sudo curl -L "https://get.daocloud.io/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
前言参考:https://www.cnblogs.com/xiaochuan94/p/11198610.html防止丢了直接拷贝过来备忘,如有侵权,请联系删除01 计数排序算法概念计数排序不是一个比较排序算法,该算法于1954年由 Harold H. Seward提出,通过计数将时间复杂度降到了O(N)。02 基础版算法步骤第一步:找出原数组中元素值最大的,记为max。第二步:创建一个新数组cou
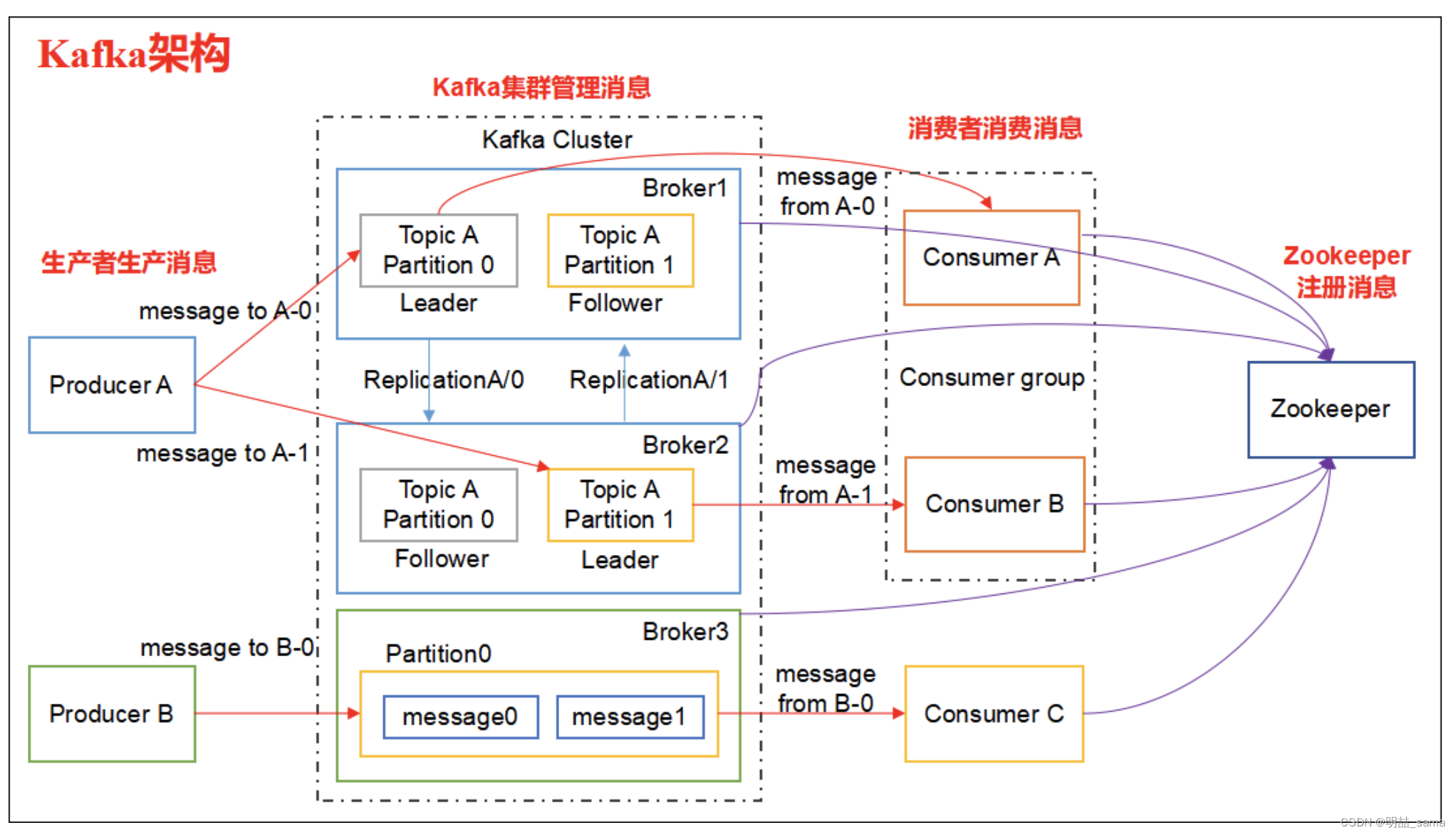
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。由于 consumer 在消费过程中可能会出现断电宕机等故障, consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
纯粹是为了记笔记,以防后面遇到类似问题,又要找一遍问题1、问题:在hue创建hive UDAF函数报错,Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.FunctionTask。创建语句:CREATE FUNCTION call_
一、生产端的消费策略二、消费端的生成策略1、range (默认分配策略)对应的实现类是 org.apache.kafka.clients.consumer.RangeAssignor将分区按数字顺序排行序,消费者按名称的字典序排序用分区总数除以消费者总数。如果能够除尽,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区2、RoundRobin基于轮询算法对应的实现类是 org.apache
执行脚本:spark-submit --class com.bigdata.SparkDemo --master yarn --deploy-mode client --driver-memory 1g /tmp/StructStreamingdemo-1.0-SNAPSHOT.jar报错信息如下Exception in thread "main" org.apache.spark.sql.Ana
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。由于 consumer 在消费过程中可能会出现断电宕机等故障, consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。