




- @transformer_WSZ
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
鼠标宏是一种自动化脚本,用于记录并重复执行一系列鼠标操作(如点击、移动、滚轮滚动等),以提高操作效率或实现复杂操作。它通常用于游戏、办公自动化、设计等领域。记录一下赛睿鼠标的宏设置。点击打开编辑器,然后点击启动,就开始录制按键。如果想关闭宏命令,则重新选择默认即可。选择按键之间无延迟,即可快速输入。选择要绑定宏命令的按键,这里以。保存并启动该宏命令。键可以看到自动化输入。
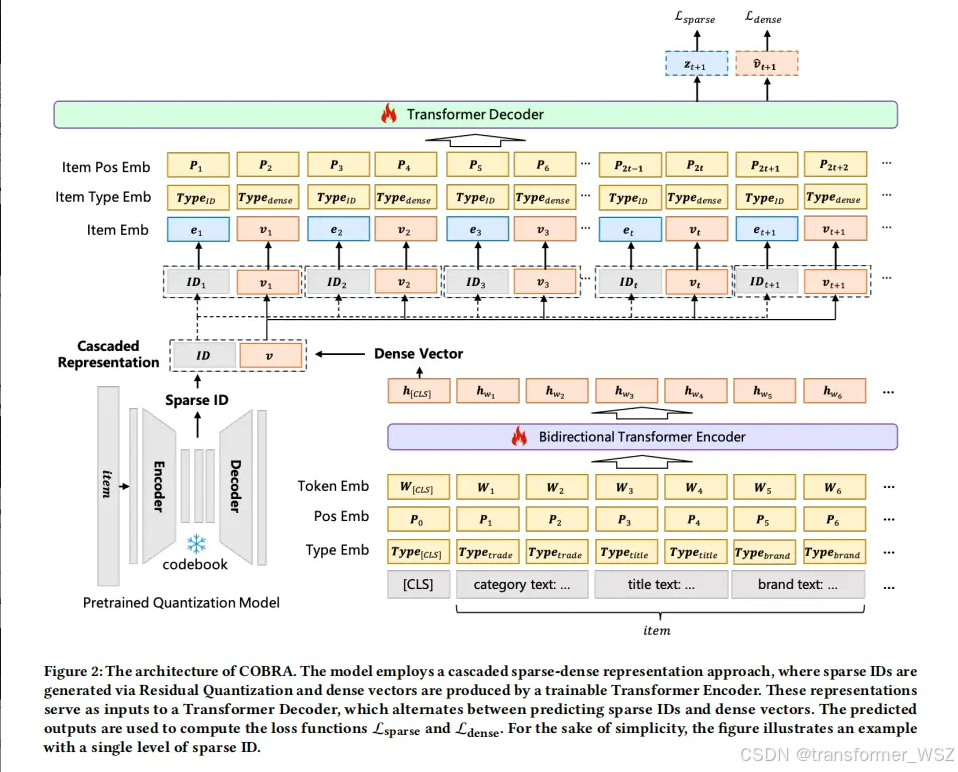
稀疏ID可以唯一表示item,有很好的区分性,但丧失了对item的细粒度信息刻画。纯文本可以准确可以item属性,但构造成prompt太长,套入到LLM中会导致资源消耗过大。那么如何结合两者的优点呢?COBRA首先根据codebook生成item的稀疏ID,该ID可以理解为item的大类别。既不过于精细,像unique id,又不过于宽泛。然后将ID序列输入到Transformer Decoder
TIGER是第一篇将Generative Retrieval 自回归生成方式应用于推荐系统的工作;它通过Semantic ID 和 Seq2Seq Transformer,突破embedding + ANN的传统限制;在冷启动、多样性、效率和泛化能力上展现强优势;适用于大规模推荐场景,尤其是content-rich、item海量、频繁上线新品的平台。
毫米波雷达是**“务实的功能性传感器”**,性价比高,全天候可靠,尤其擅长测速。激光雷达是**“精确的建模型传感器”**,能构建高精地图,是高级别自动驾驶的“眼睛”,但成本高且受天气制约。它们是智能系统感知世界的两种互补技术,共同确保了车辆或机器人在复杂环境下的安全运行。
这两天尝试了使用Github Action来自动化部署博客,踩了一些坑,在此记录一下。新建仓库存放博客源文章的仓库(Source Repo),命名随意存放编译后生成的静态文件的仓库(Page Repo),命名username.github.io配置部署密钥利用 ssh-keygen 来生成公钥和私钥:私钥放于Source仓库的 Settings -> Secrets -> Action
在面试中,遇到有些面试官会问分布式训练的有关问题,在此总结一下。分布式训练的并行方式主要分如下两种:数据并行:将数据集切分放到各计算节点,每个计算节点的计算内容完全一致,并在多个计算节点之间传递模型参数。数据并行可以解决数据集过大无法在单机高效率训练的问题,也是工业生产中最常用的并行方法。模型并行:通常指将模型单个算子计算分治到多个硬件设备上并发计算,以达到计算单个算子计算速度的目的。一般会将单个

精排正样本:曝光点击负样本:曝光未点击粗排正样本:曝光点击负样本:如果只复用精排的负样本,粗排模型对精排模型的拟合就会出现比较大的偏差。因为粗排打分高的item可能会被精排打低分,导致不能下发曝光。而精排的正负样本量很少,粗排只见到了精排的样本,对于自己打分高的item,并不知道其正负属性,在下一次打分中,可能仍然会对其打高分。因此除了精排的负样本,仍然需要从精排未下发的item中负采样一部分,作
这两种指标常用于衡量模型性能的好坏。more。
