- @sxlsxl119
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一,迁移学习是什么?别处学得的知识,迁移到新场景的能力,就是“迁移学习”。具体在实践中体现为:将 A任务上 预训练好的模型 放在B任务上,加上少量B任务训练数据,进行微调 。二,与传统学习的比较传统学习中,我们会给不同任务均提供足够的数据,以分别训练出不同的模型:但是如果 新任务和旧任务类似,同时新任务 缺乏足够数据去从头...
方法一:#include <iostream>#include <string>#include <sstream>using namespace std;int main
先占坑,以后补成自己的理解。其实我觉得,只要理解了LSTM,GRU很好理解,只是变了一下内部结构。下面这篇文章是写GRU的,写的很好https://blog.csdn.net/wangyangzhizhou/article/details/77332582...
表示目前还是懵的,智商不够,看不懂,-_-||。博主写的很好,转载过来,慢慢消化吧,原文地址:https://zybuluo.com/hanbingtao/note/581764
1、深度学习框架图:2、神经网络要解决的问题2.1、基于网络功能函数的定义(网络模型的选择,激励函数的选择,优化方法的选择)–>网络模型好坏的评估(损失函数的定义)–&a
一,循环神经网络:原文:https://zybuluo.com/hanbingtao/note/541458语言模型RNN是在自然语言处理领域中最先被用起来的,比如,RNN可以为语言模型来建模。那么,什么是语言模型呢?我们可以和电脑玩一个游戏,我们写出一个句子前面的一些词,然后,让电脑帮我们写下接下来的一个词。比如下面这句:我昨天上学迟到了,老师批评了____。我们给电脑展...
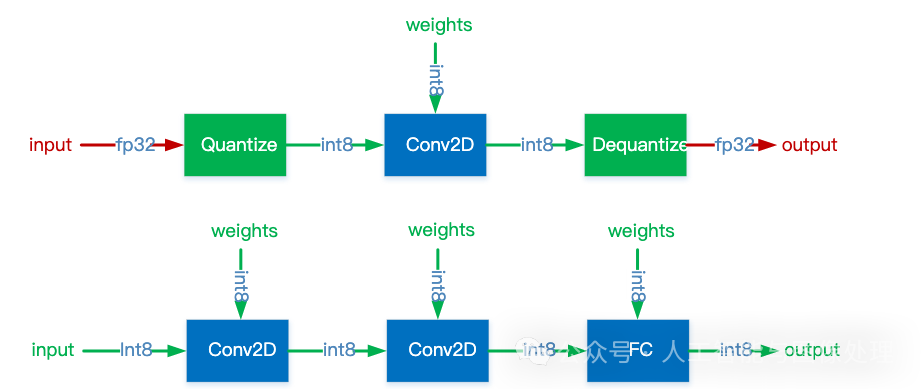
深度学习模型量化是一项重要的技术,旨在通过减少网络参数的比特宽度(比特宽度是指在特定时间内,数据传输过程中每个比特所占用的时间或空间)来减小模型大小和加速推理过程,同时保持模型性能,以便将模型部署到边缘或低算力设备上,实现降低成本、提高效率的目标。
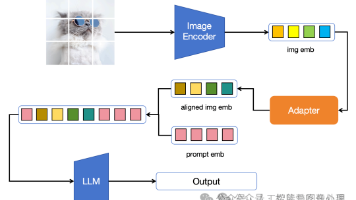
相较于之前的工作,本文的主要贡献在于将更精细的动态图像预处理方式和统一的多模态位置编码引入了多模态大模型。Qwen2VL仅要求图像的宽高能被28整除,该方式能处理更多样的长宽比。且能根据图像分辨率分配img_emb的token数量,资源消耗更加合理。统一的多模态位置emb(M-Rope)统一了图像,视频和文本。对比实验证明了该编码方式能提升模型效果。
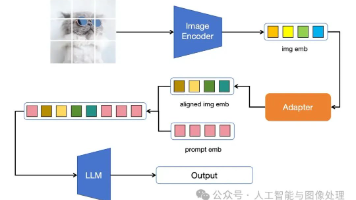
QWenVL提出来能力增强的训练阶段,并使用了B级别的对齐训练数据,M级别的能力增强数据和K级别的指令跟随数据,训练多模态大模型。能力增强训练可能较为耗费资源但能极大程度提升模型效果。后续自己构建大模型时可以考虑构建和下游任务接近的训练任务用于能力增强训练。
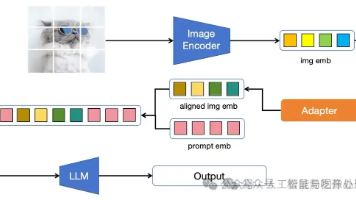
模型结构上:LLaVA仅用简单的线性链接层就完成了视觉模型与LLM的结合,结合方法简单但有效。训练数据上:LLaVA给出了一种使用ChatGPT造训练数据的方法。虽然类似的方法在语言大模型的训练中较为常见,但该文是在多模态大模型上的首次尝试。训练方法上:作者先采用了大量的易学数据训练少量参数让模型学会认图,再用少量难学的数据训练大量参数让模型学会基于图像的多轮对话和逻辑推理能力。