




- @ssp584731180
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务

因为vllm-omni 是 vLLM-Omni 通过 vLLM Ascend 插件 (vllm-ascend) 支持 NPU。所以没有根据官方文档 vllm-Omini,如果要容器化,只能运行在vllm-ascend昇腾环境中,所以 我们需要在容器中安装成功 vLLM-Omni 并打包成可以一键在GPUstack启动中启动的docker镜像。打包方式:1.启动 ascend环境特别说明:这个目录是
因为vllm-omni 是 vLLM-Omni 通过 vLLM Ascend 插件 (vllm-ascend) 支持 NPU。所以没有根据官方文档 vllm-Omini,如果要容器化,只能运行在vllm-ascend昇腾环境中,所以 我们需要在容器中安装成功 vLLM-Omni 并打包成可以一键在GPUstack启动中启动的docker镜像。打包方式:1.启动 ascend环境特别说明:这个目录是
java使用POI-TL生成docx文件,含图片以及富文本html等。

docker 安装 NFS服务端与客户端

因为vllm-omni 是 vLLM-Omni 通过 vLLM Ascend 插件 (vllm-ascend) 支持 NPU。所以没有根据官方文档 vllm-Omini,如果要容器化,只能运行在vllm-ascend昇腾环境中,所以 我们需要在容器中安装成功 vLLM-Omni 并打包成可以一键在GPUstack启动中启动的docker镜像。打包方式:1.启动 ascend环境特别说明:这个目录是
java使用POI-TL生成docx文件,含图片以及富文本html等。
docker 安装 NFS服务端与客户端
【代码】关于deepseek,千问qwq32B等大模型没有开始<think>问题的解决方案!
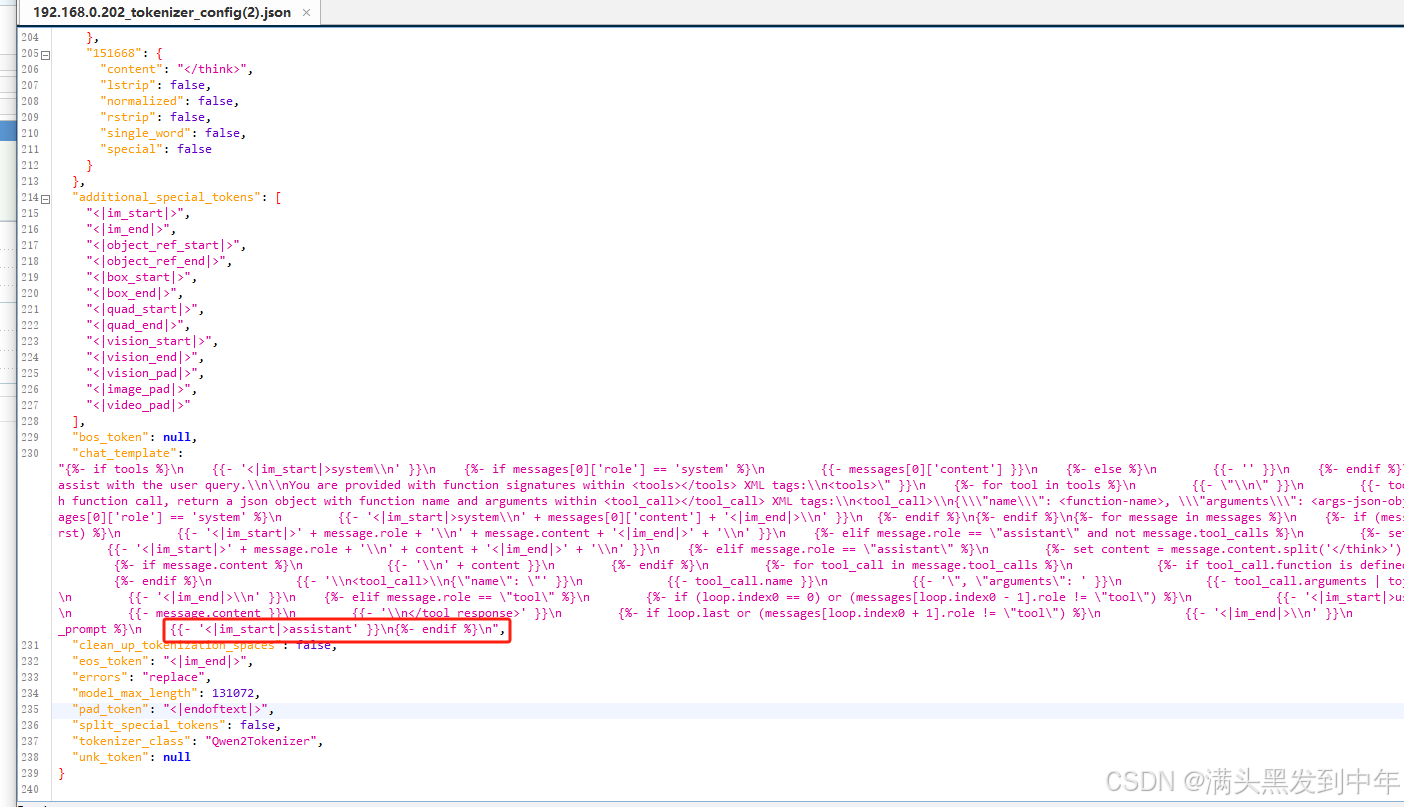
我们在使用ollma部署大语言模型的时候,如果部署的模型尺寸较大,往往在第一次加载的时候需要花费大量的时间加载模型;等加载完成后,如果长时间不调用模型,我们会发现模型已经被释放掉了,又要重新加载,导致体验感极差。