




- @songyuc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Keywords: simple这些公式是针对状态空间模型中的一个重要概率分布,即高斯分布(也称为正态分布)的一般形式。在状态空间模型中,高斯分布用于描述系统状态的不确定性,并且通常假定其满足马尔科夫性质,即当前状态只依赖于前一个状态。在这个公式中,假定状态满足马尔科夫性质,即当前状态只依赖于前一个状态,因此。表示根据前一个状态的值,生成当前状态的概率密度函数,这个概率密度函数是一个由。个条件概率
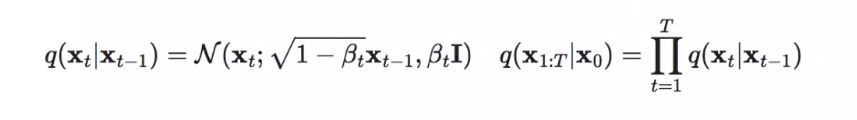
在运行一段时间后在终端会突然消失,如图所示。
就是脚本执行了一会之后,终端就回到了“等待输入”的状态,看起来脚本似乎执行完成了,这是什么原因呢,这是。时观察到一个如图所示的奇怪现象,
VSCode
1 检测框可视化1.2 添加文字1.2.1 字体大小的物理含义——“字符的高度”字体的大小可以由磅值定义,这里引用网友“插画与设计生活 ”的给出的图片,这里引用一下他的文章,表示感谢——《【字体】字体大小对照表》这里我们再引用一下百科百科的对“字体磅值”的定义:可以看到字体的大小实际上是由字符的高度来确定的;...
Keywords:1 介绍在PyTorch中定义自己的数据集类,需要继承父类Dataset,自定义的Dataset类需要实现以下三个函数:init():用来实现初始化的操作;len():用来返回数据集的样本数目;getitem(): to support the indexing such that dataset[i] can be used to geti-th sample;........
1 前言感谢蔡超老师的讲授,给予了我很大的启发~2 数值分析方法求解最优化——“数学上最优美的求解方法”2.1 最初认识数值分析求解最优化的分类器——SVMSVM是我最初学习的分类器之一,SVM线性分类器求解过程的推导还是十分优美的~使用了拉格朗日乘子法;(具体的推导过程可以参考蔡超老师讲授的PPT)2.2 为什么神经网络不适合用数值分析法求解呢?这是因为在数值分析法求解的过程中,需要计算矩阵或者
人工智能太强大了!文献阅读版ChatGPT(SciSpace),一站式科研文献阅读工具 - 知识点目录;
1 前言End-to-end目标检测算法都是一些比较厉害的模型2 End-to-end的SOTA检测模型——Deformable-DETR现在最强的端到端模型是Deformable-DETR;
1 问题描述在验证模式下运行代码的时候,出现这样的错误:Process finished with exit code 137 (interrupted by signal 9: SIGKILL)根据网上的资料,这应该是内存溢出引起的问题;2 引发原因2.1 验证样本粒子数设置过大当验证样本粒子数设置的过大时,需要大量的内存来保存检测框的结果,从而可能引发内存溢出的问题;调试方案:减小采样粒子数.