




- @songxia928_928
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
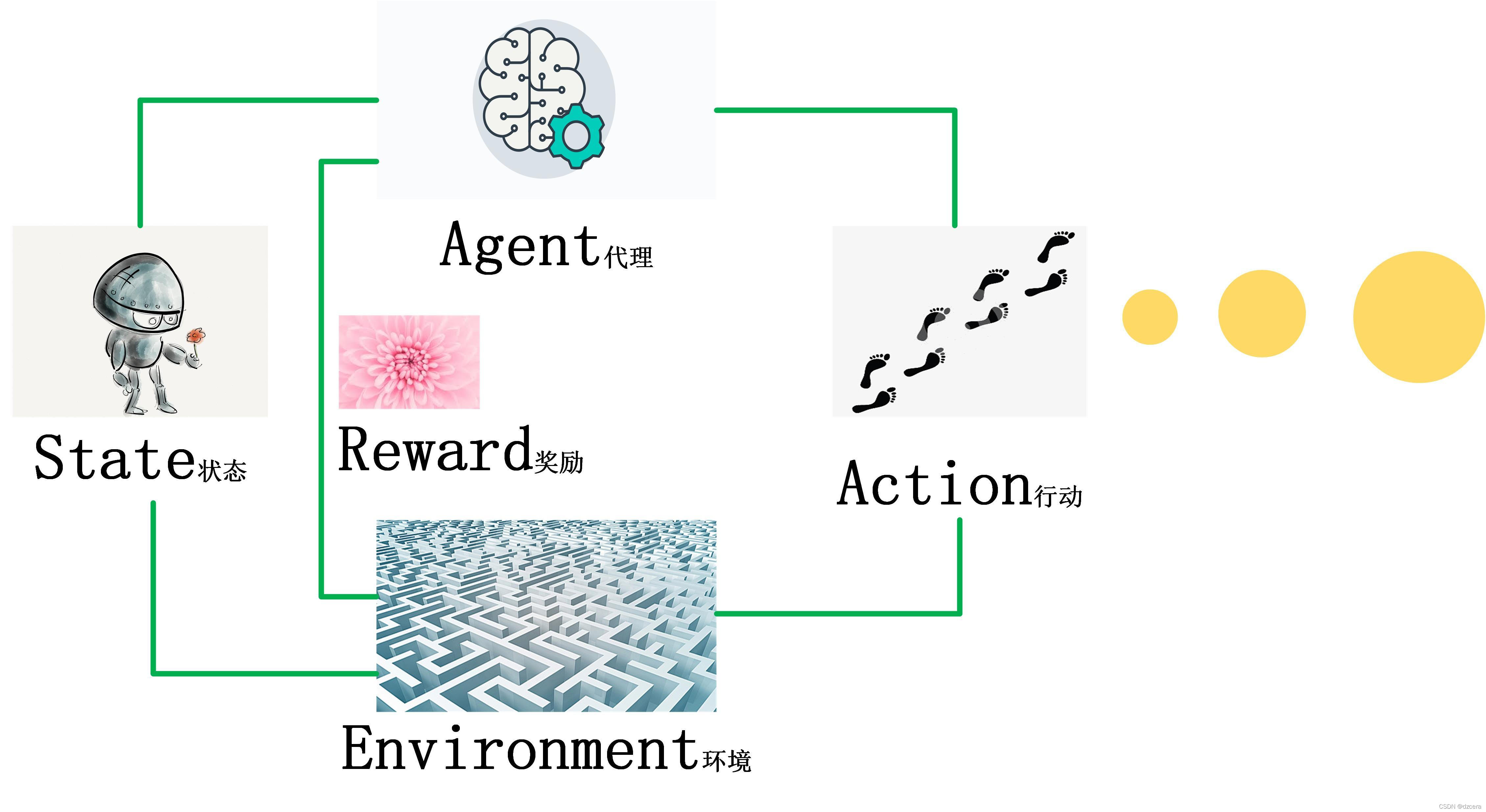
深度 Q 学习(Deep Q - Learning,简称 DQN)是强化学习领域中结合了与的算法。其核心目标在于借助深度神经网络来近似 Q 函数,从而克服传统 Q - Learning 在处理大规模或连续状态空间时所面临的计算难题。DQN 的核心思想是采用深度神经网络(通常为卷积神经网络或者多层感知机)作为函数逼近器,用以估计动作 - 值函数(action - value function),也就
Qwen2.5-Omni是首个支持文本、图像、音频、视频全模态输入与流式文本/语音输出的端到端多模态大模型。通过块处理音视频编码器将长序列多模态数据解耦,利用TMRoPE时间对齐位置编码实现音视频时序同步,创新提出Thinker-Talker架构Thinker作为多模态推理核心,处理跨模态语义融合;Talker作为双轨生成引擎,并行输出文本与自然语音,通过滑动窗口DiT模型降低流式生成延迟。针对多

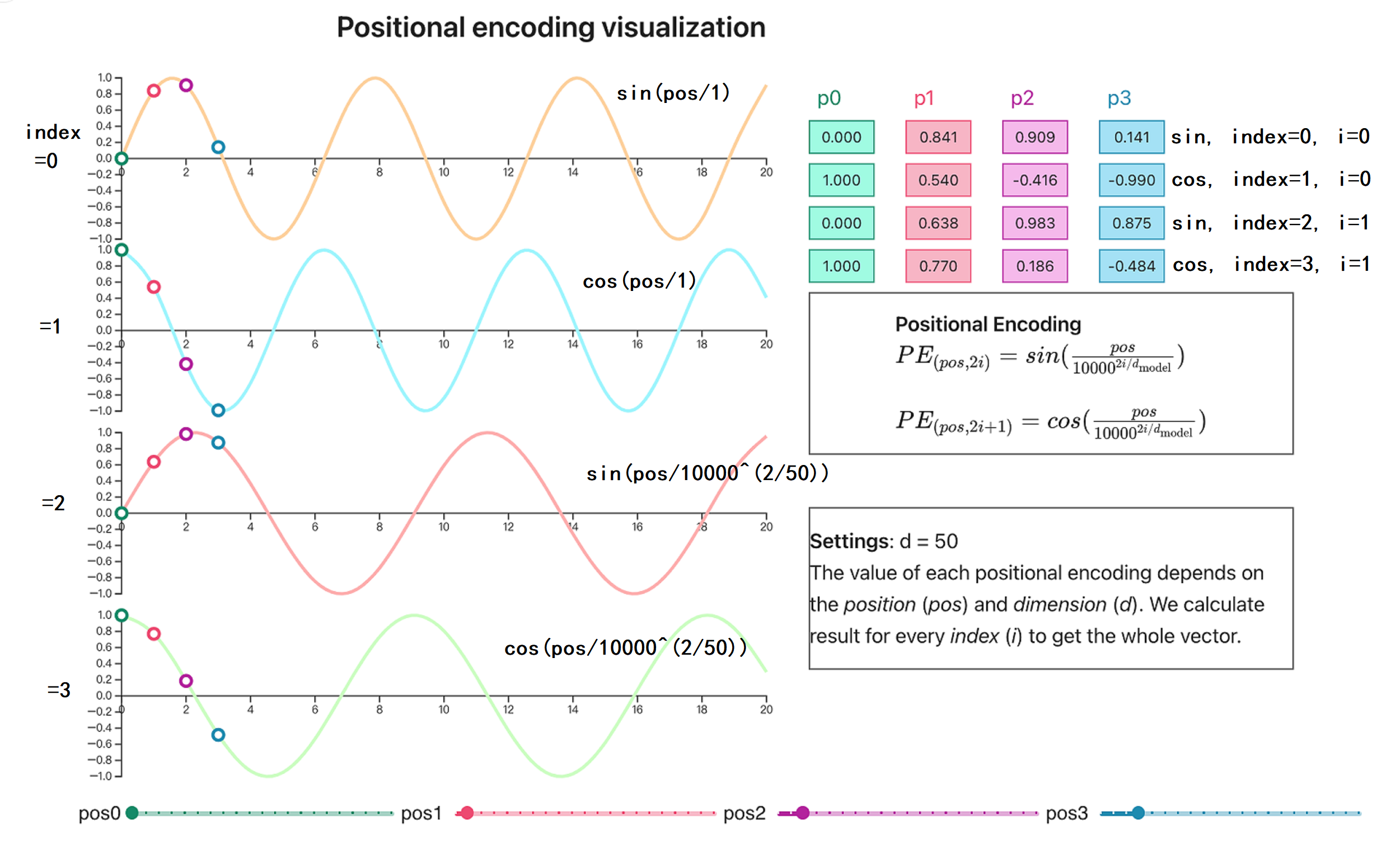
位置编码是深度学习中一个不可或缺的技术,它为模型提供了感知数据中位置信息的能力。不同的位置编码方式,如正弦和余弦位置编码、基于学习的绝对位置编码、旋转位置编码等,各有其特点和优势。在实际应用中,我们需要根据具体的任务和数据特点选择合适的位置编码方式,以提升模型的性能。随着深度学习的不断发展,位置编码技术也在不断演进,未来有望出现更高效、更强大的位置编码方法,为深度学习在各个领域的应用带来新的突破。
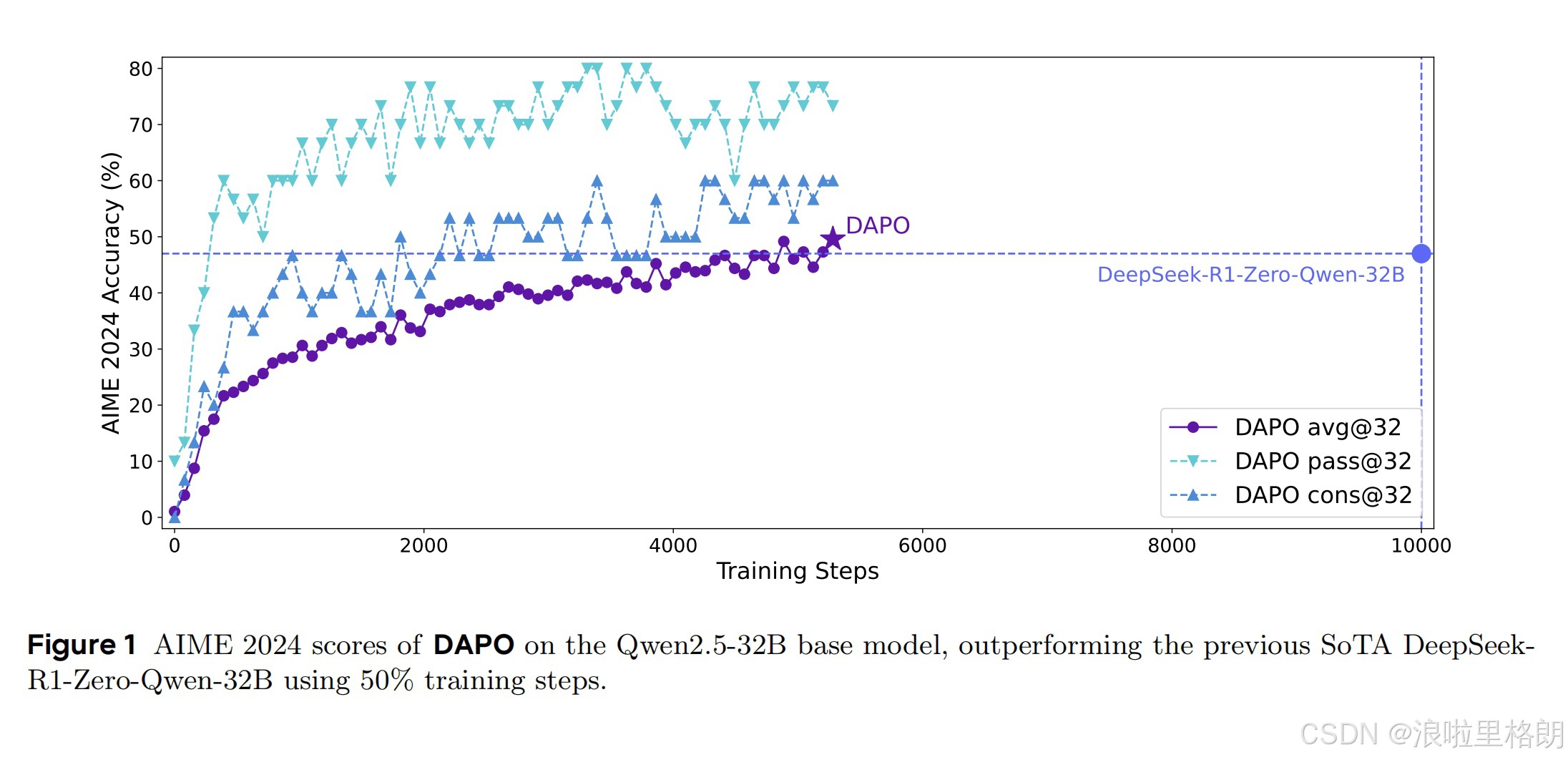
DAPO通过四大创新技术(Clip-Higher、动态采样、Token级损失、超长奖励塑形),在AIME 2024基准上实现50分的开源最优成绩,训练效率提升50%。其开源系统为行业提供了可复现的大规模RL解决方案。
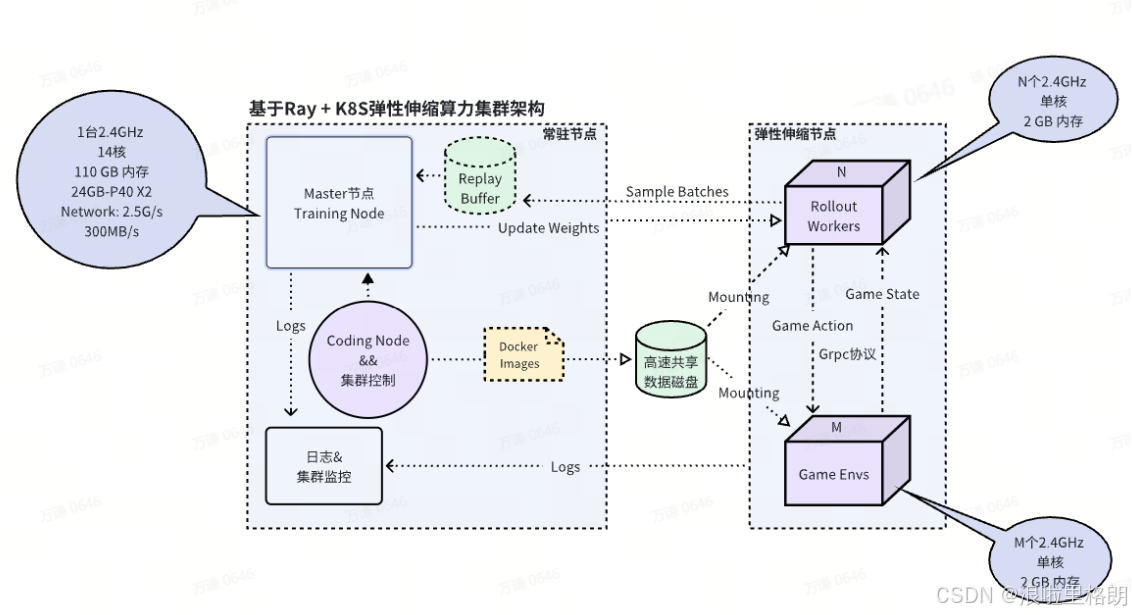
在一些复杂任务中,RLlib 的默认训练器可能无法满足需求。Ray 支持自定义分布式架构,我们可以通过ray.remote分布式环境采样器for _ in range(100): # 限制每次 episode 最大步数if done:break集中式学习器# 使用采样数据更新策略分布式训练架构# 启动多个采样器# 启动集中式学习器# 分布式训练Ray 强大的分布式计算能力为强化学习的高效训练提供了
PPO(Proximal Policy Optimization)是一种强化学习算法,是策略优化方法的现代改进版本。它结合了策略梯度方法的优势,同时通过限制策略更新幅度,保持训练的稳定性和高效性。PPO 是一种高效且稳定的强化学习算法,它在策略优化中通过截断约束限制策略更新幅度,兼具简洁性和高性能。在与 DQN、传统策略梯度、Actor-Critic 和 TRPO 的对比中,PPO 在稳定性和样本
在代码中,TRPO算法被应用于经典的强化学习任务任务目标控制小车的左右移动以保持杆子的平衡,尽可能延长杆子直立的时间。环境特征状态空间:由4个连续变量组成:小车位置;小车速度;杆子角度;杆子角速度。动作空间:包含2个离散动作:向左施加推力;向右施加推力。奖励函数:每个时间步杆子保持直立,奖励为+1。终止条件杆子角度超过阈值;小车偏离边界。
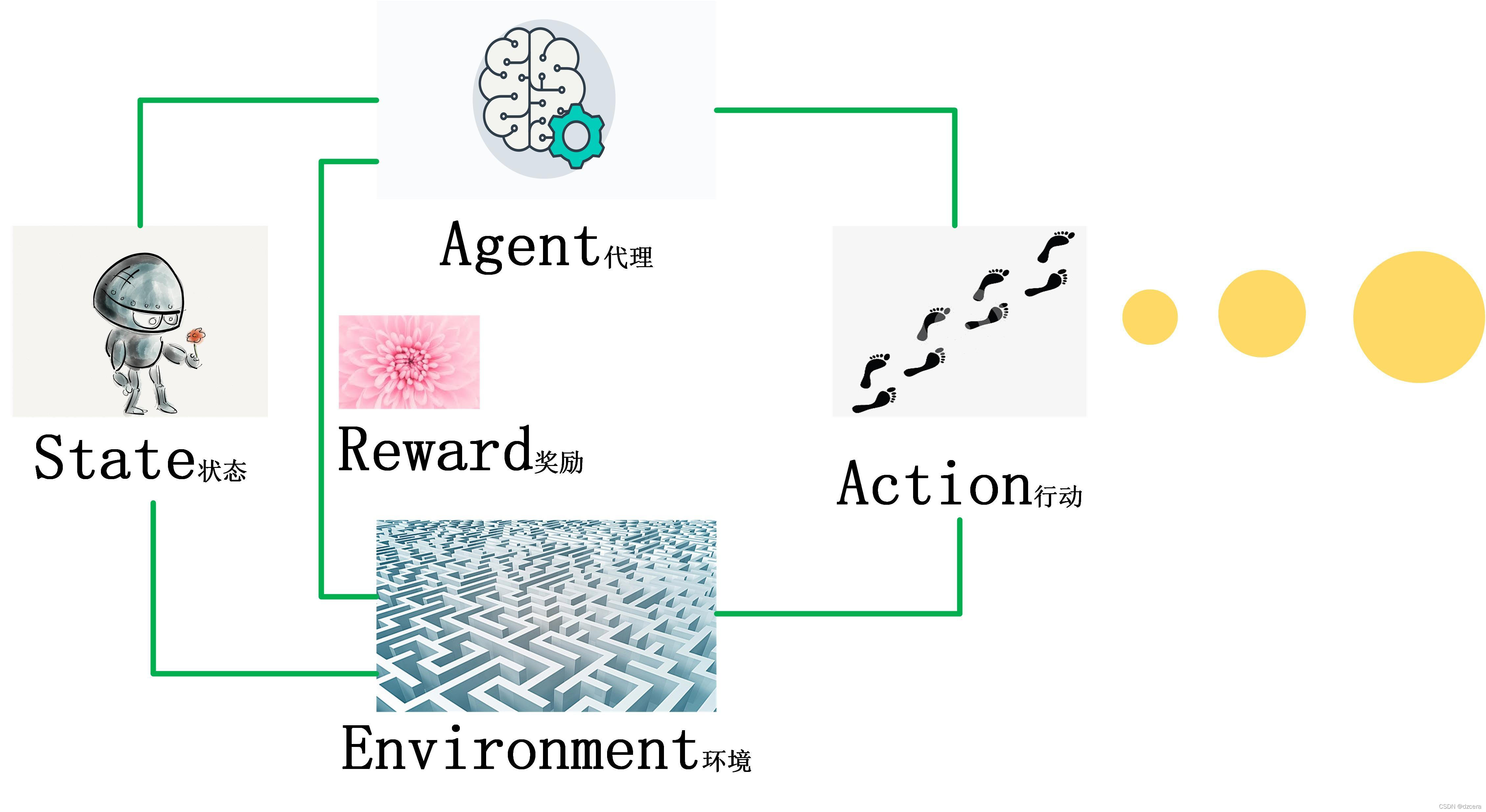
深度 Q 学习(Deep Q - Learning,简称 DQN)是强化学习领域中结合了与的算法。其核心目标在于借助深度神经网络来近似 Q 函数,从而克服传统 Q - Learning 在处理大规模或连续状态空间时所面临的计算难题。DQN 的核心思想是采用深度神经网络(通常为卷积神经网络或者多层感知机)作为函数逼近器,用以估计动作 - 值函数(action - value function),也就
Q-Learning 是一种基于值的强化学习算法,借助Qsa来预估在给定状态s下采取动作a的期望回报。在更新时,Q-Learning 采用贪婪策略,即始终选取最大的Q值。

Qwen2.5-Omni是首个支持文本、图像、音频、视频全模态输入与流式文本/语音输出的端到端多模态大模型。通过块处理音视频编码器将长序列多模态数据解耦,利用TMRoPE时间对齐位置编码实现音视频时序同步,创新提出Thinker-Talker架构Thinker作为多模态推理核心,处理跨模态语义融合;Talker作为双轨生成引擎,并行输出文本与自然语音,通过滑动窗口DiT模型降低流式生成延迟。针对多