




- @songguangfan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
常用分类算法总结分类算法总结NBC算法LR算法SVM算法ID3算法C4.5 算法C5.0算法KNN 算法ANN 算法分类算法总结分类是在一群已经知道类别标号的样本中,训练一种分类器,让其能够对某种未知的样本进行分类。分类算法属于一种有监督的学习。分类算法的分类过程就是建立一种分类模型来描述预定的数据集或概念集,通过分析由属性描述的数据库元组来构造模型。分类的目的就是使用分类对新的数据集进行划分..
什么是GoogLeNetGoogLeNet特点优化网络质量的生物学原理GoogLeNet网络结构的动机GoogLeNet架构细节Inception模块和普通卷积结构的差异辅助分类器GoogLeNet网络架构GoogLeNet训练以及样本预处理GoogLeNet测试以及测试样本处理五、GoogLeNet检测+分类MultiBox方法SelectiveSearch方法提出一种全新的深度网络架构:In.
在撰写有关 Git 的文章时,我注意到很多人都对 Git 的错误消息感到困惑。因此在这篇文章中,我将介绍 Git 的一系列错误消息,列出我认为每个错误消息中令人困惑的一些地方,并讨论当我对这些消息感到困惑时我会做什么。

常用分类算法总结分类算法总结NBC算法LR算法SVM算法ID3算法C4.5 算法C5.0算法KNN 算法ANN 算法分类算法总结分类是在一群已经知道类别标号的样本中,训练一种分类器,让其能够对某种未知的样本进行分类。分类算法属于一种有监督的学习。分类算法的分类过程就是建立一种分类模型来描述预定的数据集或概念集,通过分析由属性描述的数据库元组来构造模型。分类的目的就是使用分类对新的数据集进行划分..
参数作用取值范围影响oom_score表示进程在 OOM 时被杀死的概率,数值越高,越可能被杀死。0 到 1000根据 oom_adj 和 oom_score_adj 计算得出。oom_adj影响进程的 OOM 优先级,数值越高,进程越容易被 OOM 杀死。-17 到 15直接影响 oom_score,但 oom_score_adj 更常用。直接调整进程的 OOM 分数(oom_score),用于

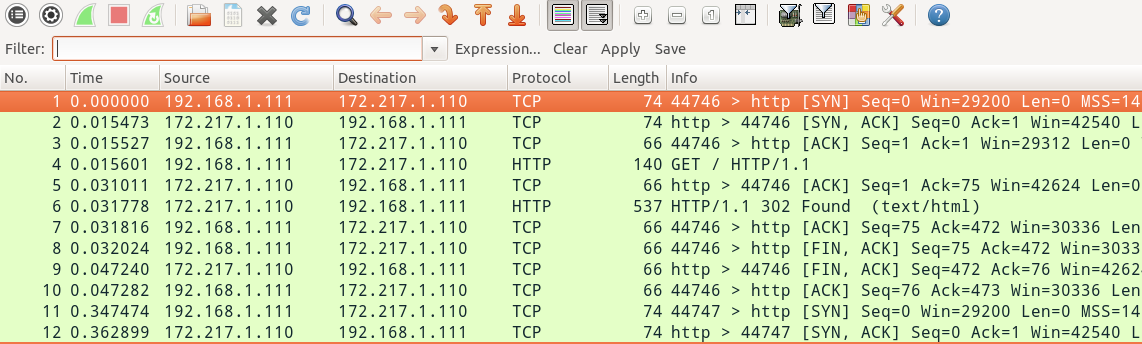
之前我一直对tcpdump抵触,但是经过几次尝试之后我想还是喜欢上了它。在讨论原因之前,我们先来了解一下 tcpdump 是什么?tcpdump 是一个帮助你分析网络流量的工具。我很长时间以来都很害怕它,拒绝学习如何使用它。现在我完全释然了,这里我带你去了解tcpdump,它 很棒,没有必要害怕它。Let’s GO!
一、影响分布式系统性能的因素主要有这些因素影响着分布式系统的性能:网络延迟、数据通信效能、计算节点处理能力、任务的分割、无法预算处理时间、任务的颠簸等等。我们在寻求分布式计算调度算法时,就是有针对性的以解决这些问题为目的,从各个角度,不同侧面,利用一种或者集中方法结合起来的形式,从而达到最优解,使得系统效率相对最高。二、几种基本的调度算法获得网络负载均衡有几个基本的方法。这些方法可以结合使...
1、事务的概念事务是用户定义的一组数据库操作序列。事务具有ACID特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。原子性指:事务包含的所有操作要么全部被执行,要么都不执行;一致性指:事务的执行结果必须使数据库从一个一致性状态转换到另一个一致性状态,一致性状态是指数据库中的数据满足...
常用分类算法总结分类算法总结NBC算法LR算法SVM算法ID3算法C4.5 算法C5.0算法KNN 算法ANN 算法分类算法总结分类是在一群已经知道类别标号的样本中,训练一种分类器,让其能够对某种未知的样本进行分类。分类算法属于一种有监督的学习。分类算法的分类过程就是建立一种分类模型来描述预定的数据集或概念集,通过分析由属性描述的数据库元组来构造模型。分类的目的就是使用分类对新的数据集进行划分..
常用关联算法总结关联算法Apriori 算法关联算法关联规则挖掘算法就是从事务数据库,关系数据库或其他信息存储中的大量数据的项集之间发现频繁出现的模式、关联和相关性。关联算法在科学数据分析、雷达信号分选、分类设计、捆绑销售、生物信息学、医疗诊断及网页挖掘等领域成果颇丰。典型的关联算法包括Aprior 算法、FP-G(Frequent pattern Growth,频繁模式增长树)算法、Fre...