




- @sinat_33087001
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
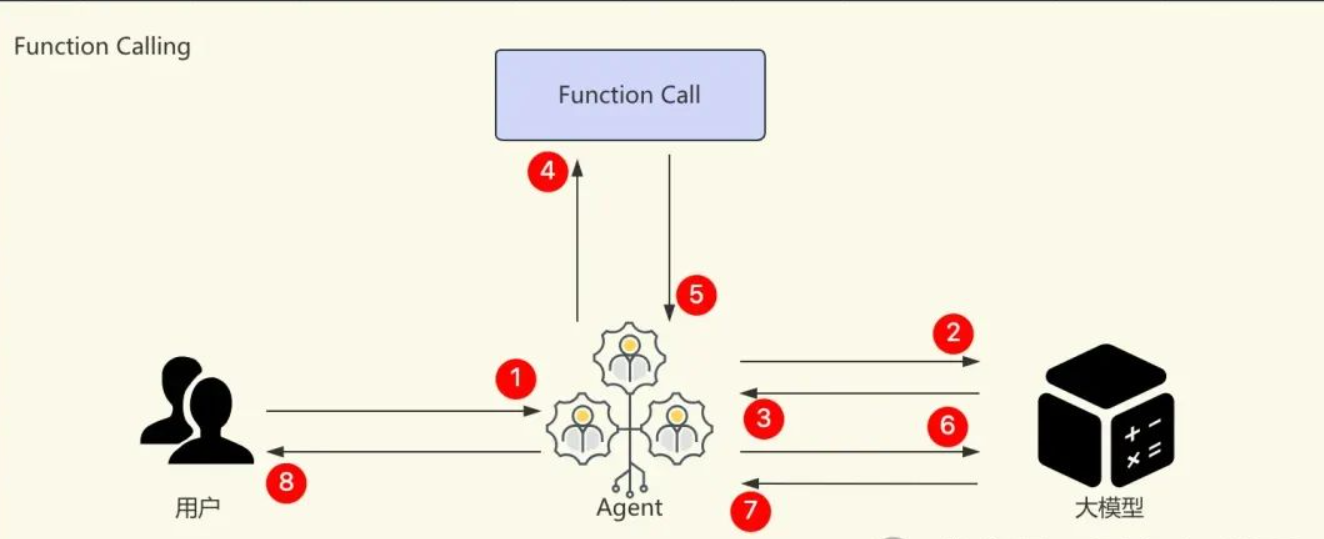
MCP(Model Context Protocol)与Function Calling(函数调用)是两种不同层面的技术方案,服务于大模型(LLM)与外部资源的交互,但设计理念和应用场景有显著区别。以下是两者的核心差异分析:MCP:开放协议层的基础设施Function Calling:特定模型的增值功能MCP适用场景Function Calling适用场景两者可结合使用:例如,在电商场景中,MCP
总的来说AI主要由算法、算力、数据组成,算法是核心。LLM是基于Transformer架构的算法成果,属于NLP领域关键技术,赋予AI理解和生成语言的能力。如果把AI AGENT看作人工助手,LLM就是其大脑,提供智能核心。AIGC则基于LLM等技术,生成语言、图像、音频等内容,就像人基于大脑的一些语言和视觉的表达。举个例子:云雀模型是LLM,豆包的问答查询基于此,是AIGC在语言领域的应用;图片

在我看来,AI时代企业业务架构正从传统三层架构,逐步升级为六层全新技术架构,整个演进过程不仅新增了Agent编排治理、大模型服务两大核心层级,还推动业务能力走向原子化拆解,同时把业务交互从传统固定页面操作,升级为更灵活的自然语言对话模式。这种架构变革也直接带动了团队人员结构与工作模式转变,一线业务人员能够自主搭建轻量化业务应用,传统后台研发人员出现明显职业分流,行业也顺势催生了智能体治理、模型工程
本文深入解析Go语言协程(Goroutine)的设计思想与实现原理。主要内容包括: Goroutine本质是用户态轻量级协程,通过go关键字创建,由Go运行时调度而非操作系统内核管理。 底层采用GMP调度模型:G代表协程,M是内核线程,P是逻辑处理器。三者协作实现高效的用户态调度,通过Mermaid图展示了完整的调度流程。 详细分析了Goroutine的生命周期状态机(Grunnable、Grun
本文深入解析Go语言协程(Goroutine)的设计思想与实现原理。主要内容包括: Goroutine本质是用户态轻量级协程,通过go关键字创建,由Go运行时调度而非操作系统内核管理。 底层采用GMP调度模型:G代表协程,M是内核线程,P是逻辑处理器。三者协作实现高效的用户态调度,通过Mermaid图展示了完整的调度流程。 详细分析了Goroutine的生命周期状态机(Grunnable、Grun
本文通过对比Java与Go语言的基础语法差异,帮助Java开发者快速掌握Go语言核心特性。主要内容包括:1) Go程序入口为main包下的main函数,无需类包装;2) 变量声明采用"变量名 类型"格式,支持短变量声明;3) 分支判断if无需括号,支持临时变量定义;4) 循环仅保留for语法,可替代while;5) 切片(slice)作为动态数组替代Java的ArrayList;6) 函数原生支持
根据不同的业务需求和场景,选择适合的数据库类型至关重要。以下是一个优化后的表格展示,涵盖了管理型系统、大流量系统、日志型系统、搜索型系统、事务型系统、离线计算和实时计算七大类业务系统的数据库选型建议。先明确下NoSQL的分类。

之前聊过Redis的分布式锁并且基于理论【Redis从入门到放弃系列 十】Redis的事务机制进行过代码实践【Redis从入门到放弃系列 十一】Redis分布式锁实战,但是其实只是对分布式锁的一个简单理解,对于其中可能的问题并没有过多讨论,甚至对于真实企业场景中的分布式锁,之前的那个也许只是个玩具,存在诸多问题...
实际上,关于Redis事务的说法“Redis 的事务只能保证隔离性和一致性(I 和 C),无法保证原子性和持久性(A 和 D)”并不完全准确。下面我将分别解释Redis事务的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
最近遇到一个问题,移动端的表情或者一些emoji是4字节的,但是utf-8是3字节的,查了很多网上的解决方法,最后提供一套自己的解决方案。如果当前的困境是:自己的mysql版本为5.5.3以前(版本为5.5.3以前将不能使用utf-8mb4编码),需要重装更高版本的mysql,然后获得该编码。1,检查自己当前数据库版本使用命令:select version();如果发现当前的数据库版本在5