




- @sinat_28442665
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文分享了Kimi Claw AI助手的初体验,重点介绍了如何配置飞书机器人功能。通过内置Skill,用户只需输入指令即可获取详细配置方案。文章提供了完整的配置流程截图,包括插件更新、飞书应用创建、权限设置、机器人加入群聊等步骤,并展示了机器人的实际问答效果。作者认为这类AI助手未来将在工作中发挥更大作用,并邀请读者共同探讨AI应用的可能性。全文配有详细的操作截图和官方文档链接,为技术爱好者提供了

细粒度图像分析(FGIA)是计算机视觉和模式识别中一个长期存在的基本问题,是一系列实际应用的基础。FGIA的任务是分析下属类别的视觉对象,例如鸟类物种或汽车模型。细粒度图像分析固有的小类间变化和大类内变化使其成为一个具有挑战性的问题。利用深度学习的进步,近年来我们见证了以深度学习为动力的FGIA的显著进步。在本文中,我们对这些进展进行了系统的综述,试图通过整合两个基本的细粒度研究领域——细粒度图像

MySQL安装与Python数据分析实战 1. MySQL安装指南 提供Windows系统安装教程,包含下载地址和安装步骤截图 建议最小化安装仅Server端 包含MySQL命令行客户端使用示例 2. 数据库管理工具 推荐Navicat图形化管理工具 展示连接建立和表管理界面截图 3. Python数据分析实战 基于中信书店场景的完整数据分析项目 包含4个核心模块: 模拟数据生成脚本 Flask后
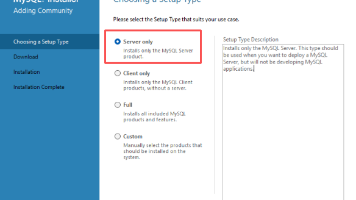
MySQL安装与Python数据分析实战 1. MySQL安装指南 提供Windows系统安装教程,包含下载地址和安装步骤截图 建议最小化安装仅Server端 包含MySQL命令行客户端使用示例 2. 数据库管理工具 推荐Navicat图形化管理工具 展示连接建立和表管理界面截图 3. Python数据分析实战 基于中信书店场景的完整数据分析项目 包含4个核心模块: 模拟数据生成脚本 Flask后
docker 占用系统空间太大了,整体迁移到挂载的其他磁盘

增强技术对于提升 YOLO 模型的鲁棒性和性能至关重要,通过引入训练数据的数据增强,帮助模型更好地泛化到未见数据。这些设置可以根据数据集和任务的具体要求进行调整。尝试不同的值可以帮助找到最佳的增强策略,从而实现最佳的模型性能。

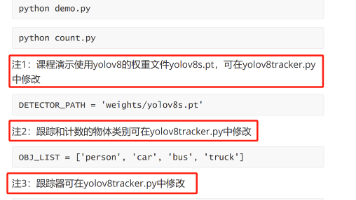
本文记录了在Win11系统上搭建YOLOv8训练环境的过程。关键步骤包括:1)使用conda创建Python3.9虚拟环境;2)安装CUDA版本的PyTorch及相关组件;3)通过源码方式安装ultralytics库;4)解决lap库安装失败的问题(最终通过conda-forge源安装成功)。环境验证显示已成功安装torch 2.4.0+cu124、torchvision 0.19.0+cu124
细粒度图像分析(FGIA)是计算机视觉和模式识别中一个长期存在的基本问题,是一系列实际应用的基础。FGIA的任务是分析下属类别的视觉对象,例如鸟类物种或汽车模型。细粒度图像分析固有的小类间变化和大类内变化使其成为一个具有挑战性的问题。利用深度学习的进步,近年来我们见证了以深度学习为动力的FGIA的显著进步。在本文中,我们对这些进展进行了系统的综述,试图通过整合两个基本的细粒度研究领域——细粒度图像
服务器环境: Windows Server 2012 R2 64位操作系统,基于x64的处理器缘由: 升级服务器驱动之后,发现在cmd窗口下使用 nvidia-smi.exe相关命令查看GPU情况时,报错如下:Failed to initialize NVML: Unknown Error额,网上查了一堆资料,回头发现250,难受我认为可能有效的解决方法为:步骤一:因为是新服务器,所以...
RuntimeError: CUDA out of memory. Tried to allocate 1018.00 MiB (GPU 0; 7.79 GiB total capacity; 4.72 GiB already allocated; 853.50 MiB free; 1.52 GiB cached) 享受学术探讨的欢乐,传递温暖,希望能够帮助到刚刚入门的同学文章目录具体报错简单分析
