- @shendong70
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
将经验沉淀为可复用技能,是人类学习亘古不变的模式。人们不会每次都从零着手处理任务,而是不断把反复实操、示范演示、试错经历与专业指导,转化为可复用的流程。这一知识外化过程历经漫长演变:从具象的实操技艺,到成文的工程规范,再到数字化工具与可编程工作流,如今已然迈入智能体原生技能生态阶段。技能如同智能体的肌肉记忆,智能体无需重复分步推理,在反复任务中灵活调取、组合、优化与管控。
Claude Code 的提示词体系呈现出 **高度工程化** 的特征:通过明确的角色分工(10 个作用域)、强约束的指令风格(12 个语法特点)以及丰富的示例与反例,有效地引导大语言模型在复杂软件工程任务中表现出稳定、安全、高效的行为。这些特点的设计思路(如并行效率建议、强制输出格式、安全限制声明)对于构建生产级的 AI Agent 提示词具有直接的借鉴意义。

大模型对话系统面临的核心挑战在于有限的上下文窗口与无限增长对话历史之间的矛盾。上下文压缩的重要性体现在三个层面:成本控制、响应延迟、信息保真。我们可以通过学习Claude Code 的上下文压缩机制,使大模型应用系统在**速度、成本和保真度之间寻求动态平衡**。

记忆体是Agent**智能化、拟人化、规模化**的必要条件;但在**存储、检索、一致性、遗忘、隐私**上仍有显著工程与算法瓶颈,是下一代Agent进化的核心攻坚方向。我们可以通过学习Claude Code 的内存管理机制,使大模型应用系统在**速度、成本和保真度之间寻求动态平衡**。

大模型 Agent 的记忆系统中,哪些应该存储,哪些不应该存储?本文详细分析了 Claude Code 记忆系统的设计和实现,从记忆的四个类型(用户记忆、反馈记忆、项目记忆、参考记忆)、记忆冲突、记忆压缩等角度中寻找记忆的存储规则,最后总结出了记忆存储的设计的十大核心原则。
大语言模型本身是无状态的——每次调用都从零开始,它不记得任何事情。这个根本约束决定了所有 Agent 框架都必须在模型外面搭一套记忆系统,并回答四个架构问题:**存什么、存在哪、怎么取、怎么管**。
目前的 AI 编程助手通常只有“短期记忆”,一旦关闭当前的对话窗口,之前的项目背景、架构约定等上下文就会丢失。本文介绍了 Claude-mem 在 Claude code 流程中关键节点使用钩子的设计方法,完成不修改Claude code 的源码,实现持久化长期记忆。这个方法为我们在设计其他 Agent 框架增加记忆提供了有益的借鉴。
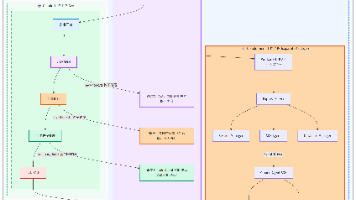
【代码】智能体记忆存储设计十大原则。

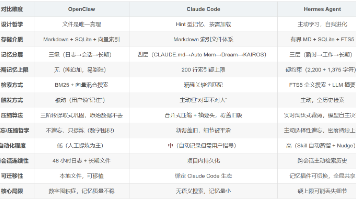
本文依据 OpenClaw 的 v2026.4.22 版本,重点分析了 OpenClaw 的记忆系统的文件存储结构和数据库存储结构,以及文件和数据库的存储关系。并简单的介绍这些存储的数据是如何在业务之间流转的。
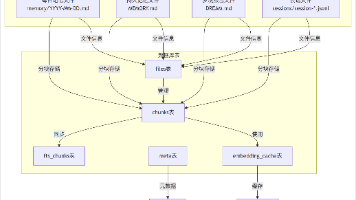
本篇继续 OpenClaw 记忆系统分析系列,介绍了 OpenClaw 记忆系统的预加载过程。