




- @selifecn
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
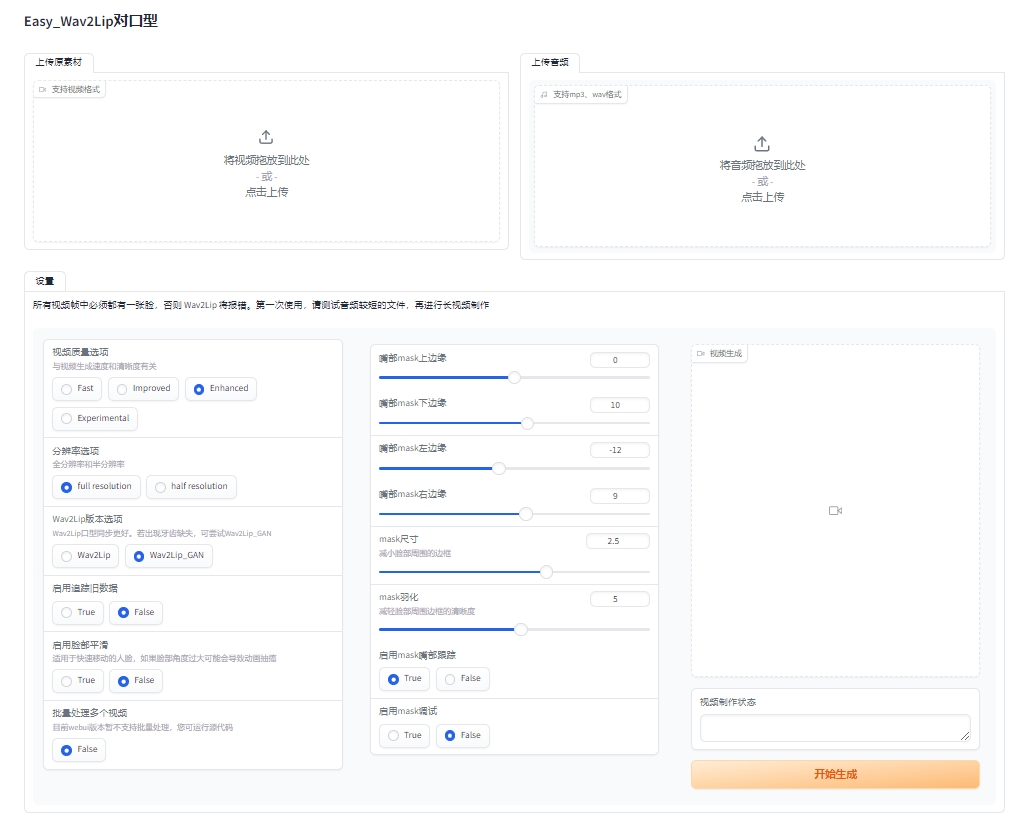
Easy_Wav2Lip是使用视频和音频合成新的视频Easy-WAV2lip是目前最成熟的数字人口型算法。
孙思邈中医药大模型(简称: Sunsimiao)希望能够遵循孙思邈的生平轨迹, 重视民间医疗经验, 不断累积中医药数据, 并将数据附加给模型, 致力于提供安全、可靠、普惠的中医药大模型

花了68元和一天时间,终于把剪映数字人生成原理搞清楚了

这一次我们主要讲如何用虚幻5创造一个可以用facegood驱动的3D数字人

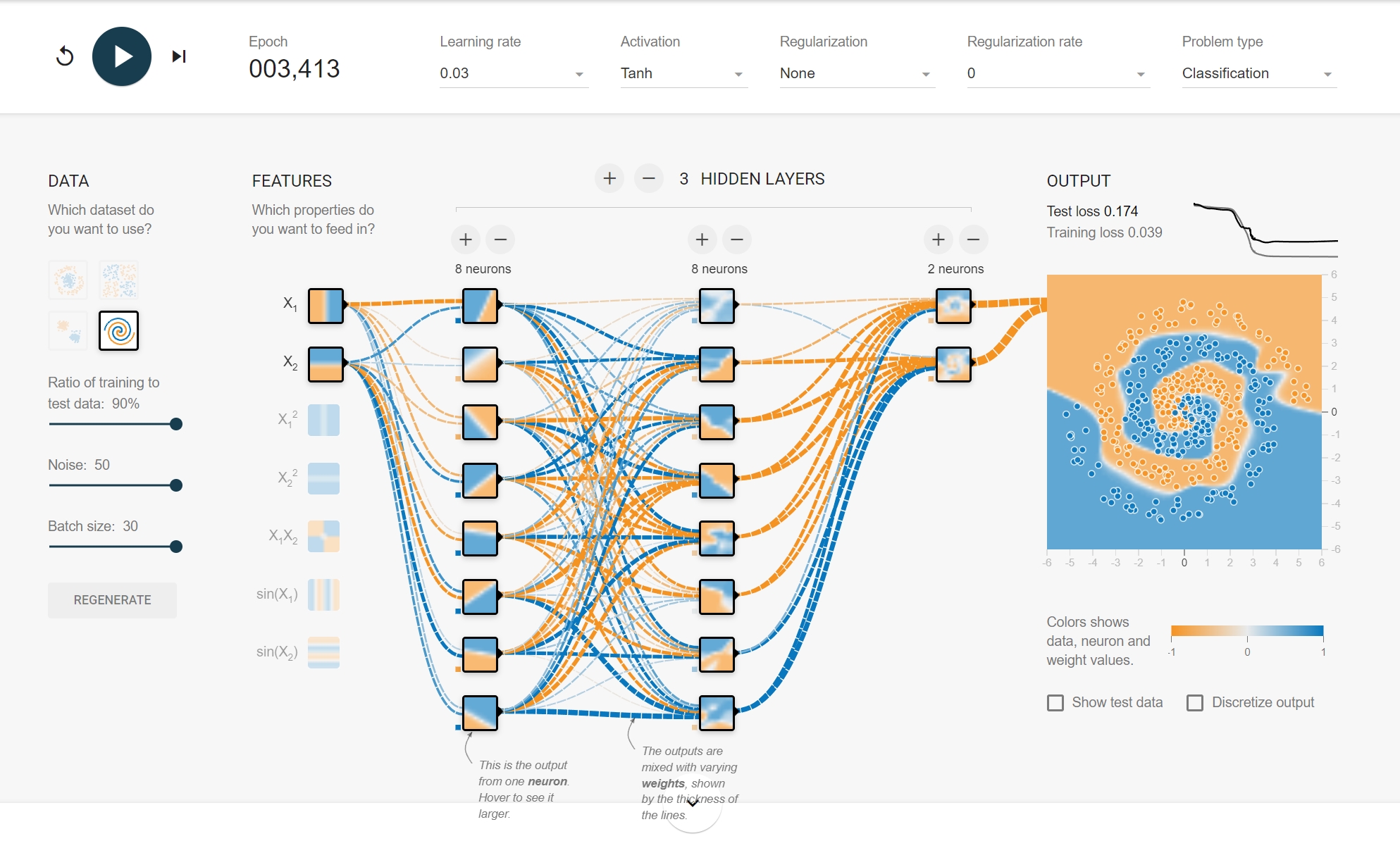
TensorFlow Playground的界面分为几个主要部分,每个部分都是理解和使用这个工具的关键。下面我们将详细介绍“数据(DATA)”、“特征(FEATURES)”、“隐藏层(HIDDEN LAYERS)”以及“输出(OUTPUT)”等参数的用法及含义。能够设置数据分布类型和测试集比例,批量大小、隐藏层、神经元个数,点击运行后就能直观的看到神经网络的训练过程演示,简直是深度学习初学者的福音
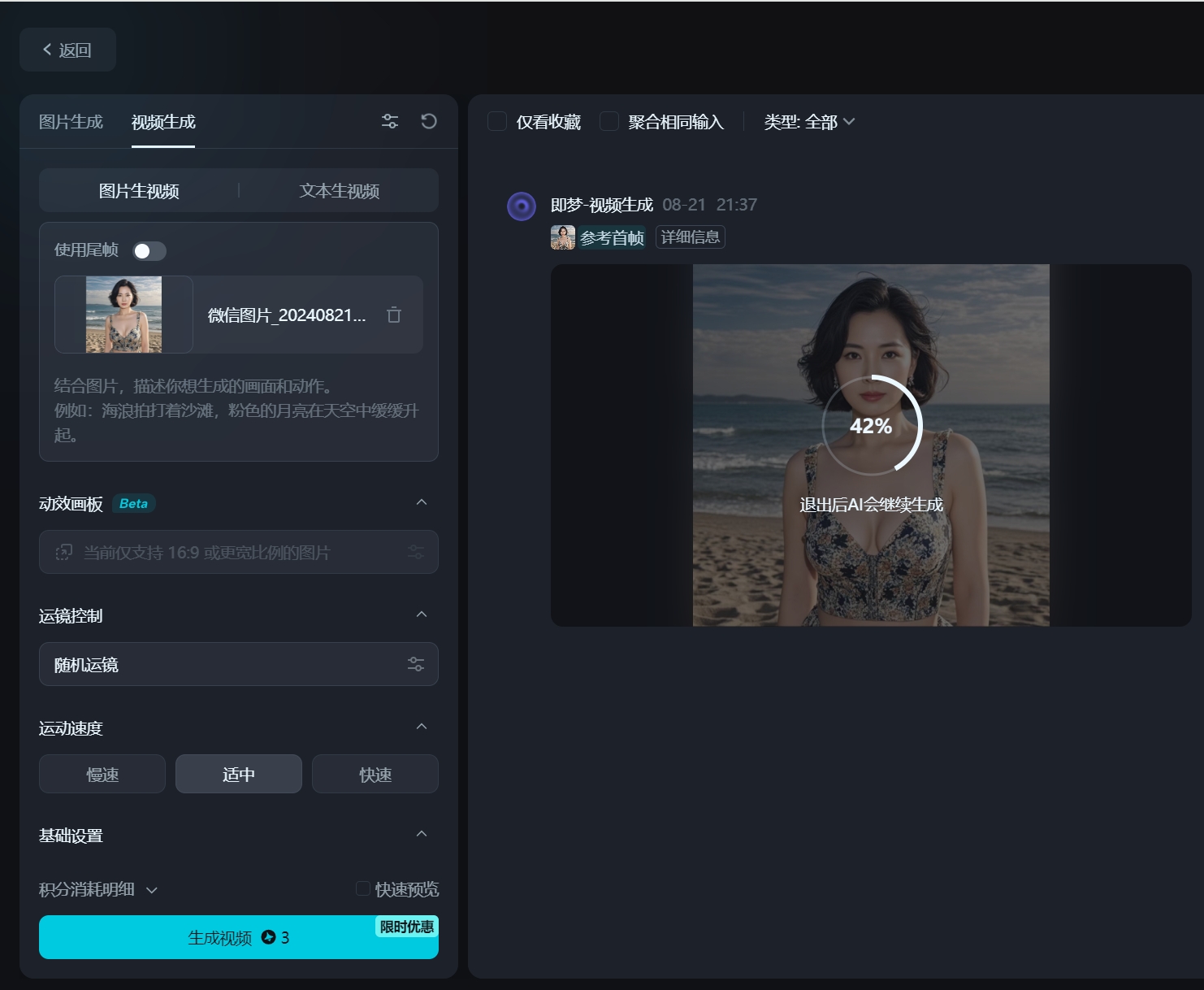
即梦Dreamina是由抖音开发的一款AI视频和绘画生成工具,旨在通过简单的文案或图片输入,快速生成优质视频片段和图片。即梦,即刻造梦。为您提供AI绘画和AIGC视频创作体验。
孙思邈中医药大模型(简称: Sunsimiao)希望能够遵循孙思邈的生平轨迹, 重视民间医疗经验, 不断累积中医药数据, 并将数据附加给模型, 致力于提供安全、可靠、普惠的中医药大模型
import cv2break使用示例1. 从视频中提取帧并进行特征匹配。2. 使用这些匹配特征来估计相机的相对位姿。3. 使用相机位姿和匹配特征三角化出3D点。4. 最后用Open3D库可视化生成的3D点云。这是一个基础的Python框架,可以在此基础上进行优化和扩展,例如加入更多的图像处理技术或使用更高级的3D重建算法。

Wav2Lip技术可以让视频中的人物根据输入的音频生成匹配的唇形动作,从而实现口型与语音同步的效果。生成器G GG负责生成目标口型的人脸图像,由三部分组成:身份编码器(Identity Encoder)、语音编码器(Speech Encoder)和人脸解码器(Face Decoder),这三部分均是由堆叠的2D卷积层组成。简单来说,就是通过分析音频信号中的语音信息,从而生成出与语音内容相匹配的口型
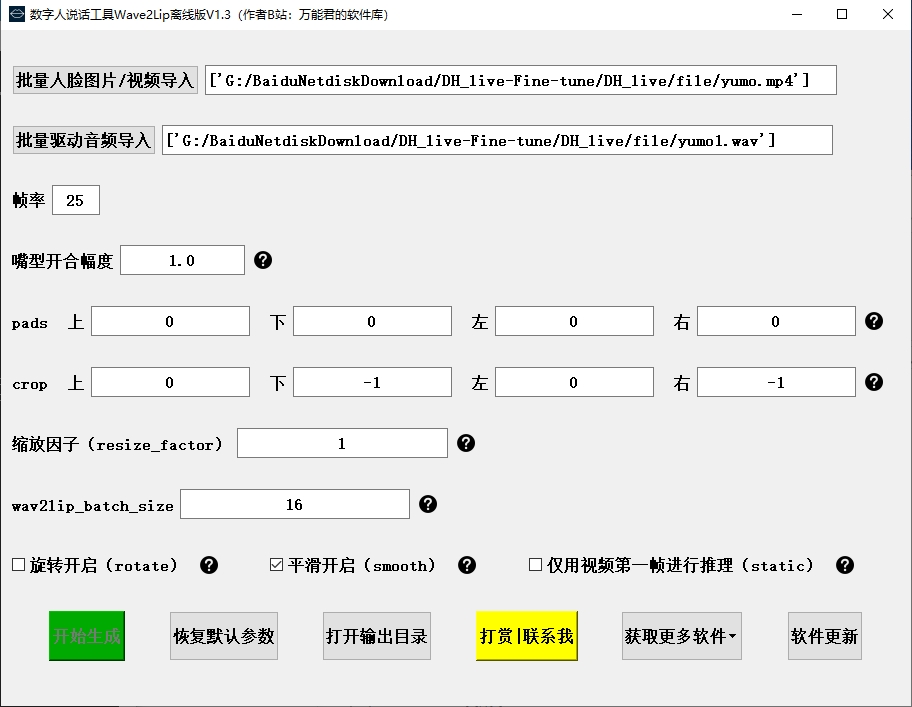
花了68元和一天时间,终于把剪映数字人生成原理搞清楚了