




- @qq_56908984
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
HoST(Learning Humanoid Standing-up Control across Diverse Postures)是 RSS 2025 的 Best Systems Paper Finalist 论文,研究人形机器人从倒地、倚靠、半坐卧等多样初始姿态自主站起,并将仿真策略直接部署到真实机器人。

X-AnyLabeling是一款集成了AI模型的通用视觉数据标注工具,支持图像分类、目标检测、实例分割、OCR等多类任务。其核心特点是将模型推理与人工标注结合,通过先自动生成候选标注再人工修正的方式提升效率。工具采用PyQt5构建界面,支持多种标注格式转换,内部使用XLABEL作为中间数据格式。安装时需Python 3.10环境,提供CPU/GPU版本。项目开源且可扩展,适用于复杂视觉数据标注场景

Legbot Lab项目摘要 Legbot Lab是一套面向四足机器人的强化学习运动控制工程,基于PPO算法和非对称Actor-Critic架构,结合仿真训练与实物部署的完整链路。项目提供两个核心分支: PPO分支与扩展教师—学生并发学习框架(CTS)和专家混合网络(MoE)分支。
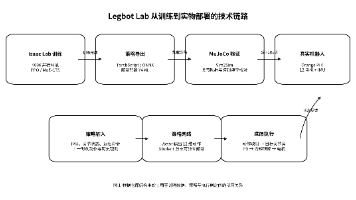
Go2 RL Gym是一个基于IsaacGym的四足机器人强化学习训练框架,支持Unitree Go2机器人的仿真训练和实机部署。项目提供多算法支持(PPO、CTS等)和地形课程学习能力,通过域随机化实现Sim-to-Real迁移。核心架构包含仿真环境、RL算法库和部署模块,其中CTS算法采用师生网络协同训练,教师网络利用特权信息指导学生网络,通过潜在表示蒸馏实现知识迁移。项目实现了从GPU并行训
Git 项目维护命令指南摘要 本文提供了全面的 Git 版本控制操作指南,涵盖从项目初始化到日常维护的全流程。主要内容包括: 项目上传 GitHub:详细介绍了三种上传方式,包括本地项目初始化推送、空仓库克隆推送和保留历史的迁移方法。 基础配置:设置用户名、邮箱、默认分支和拉取策略等基本配置项。 日常开发流程:包含文件添加、提交、状态查看和日志查询等常规操作命令。 分支管理:完整的分支操作指南,包

本文对 RSS 2021 发表的 RMA(Rapid Motor Adaptation)算法进行系统解读。RMA 提出了一种**基础策略 + 自适应模块**的两阶段解耦架构,使四足机器人能够在**不到 1 秒内**实时在线适应未知环境。该方法完全在仿真中训练,无需任何域知识或真实世界数据,即可零微调部署到 Unitree A1 机器人上。在沙地、泥地、草地、楼梯、可变形表面等多样化真实地形上,RM

本文提出了一种通用的人形机器人运动重定向方法GMR,解决了人体动作到机器人运动跟踪中的关键挑战。通过人体-机器人关键刚体匹配、静止姿态对齐、非均匀局部缩放和两阶段差分逆运动学优化,GMR显著减少了脚底滑移、地面穿透等常见伪影。实验表明,相比PHC和ProtoMotions等现有方法,GMR生成的参考动作使强化学习策略在21段LAFAN1动作上的成功率和跟踪精度更高,接近工业闭源数据的水平。研究证实

摘要 本文提出BeyondMimic框架,通过两阶段方法实现双足人形机器人的通用运动控制。第一阶段采用统一强化学习框架训练多种人类动作的高质量跟踪策略;第二阶段将这些策略蒸馏到潜在动作空间,构建状态-潜变量扩散模型作为运动先验。在部署阶段,通过扩散模型的分类器引导机制,无需重新训练即可实现多种任务的零样本组合控制,如速度跟踪、航点导航和障碍规避等。实验在Unitree G1机器人上验证了该框架的敏

legged_control 是一个基于 OCS2 和 ros-control 的开源足式机器人控制框架,采用 NMPC(非线性模型预测控制)和 WBC(全身控制)的分层架构。该框架支持 Unitree A1、Aliengo 和 Go1 等机器人,具有高效实时控制能力,可快速部署到真机。系统通过上层 NMPC 求解最优轨迹(100-200Hz),下层 WBC 实现关节力矩控制(500Hz-1kHz
本文提出了一种并行教师-学生强化学习框架(CTS),用于解决腿式机器人在非结构化地形上的运动控制问题。传统教师-学生范式存在两阶段训练效率低、学生策略仅模仿教师而缺乏强化学习目标引导等缺陷。CTS创新性地将教师策略和学生策略在强化学习范式下并行训练,通过共享策略网络和价值网络,同时结合特权编码器的强化学习训练和本体感知编码器的监督学习。该方法在仿真和实物实验中均展现出优于传统方法的性能,特别是在面
