




- @qq_44926214
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
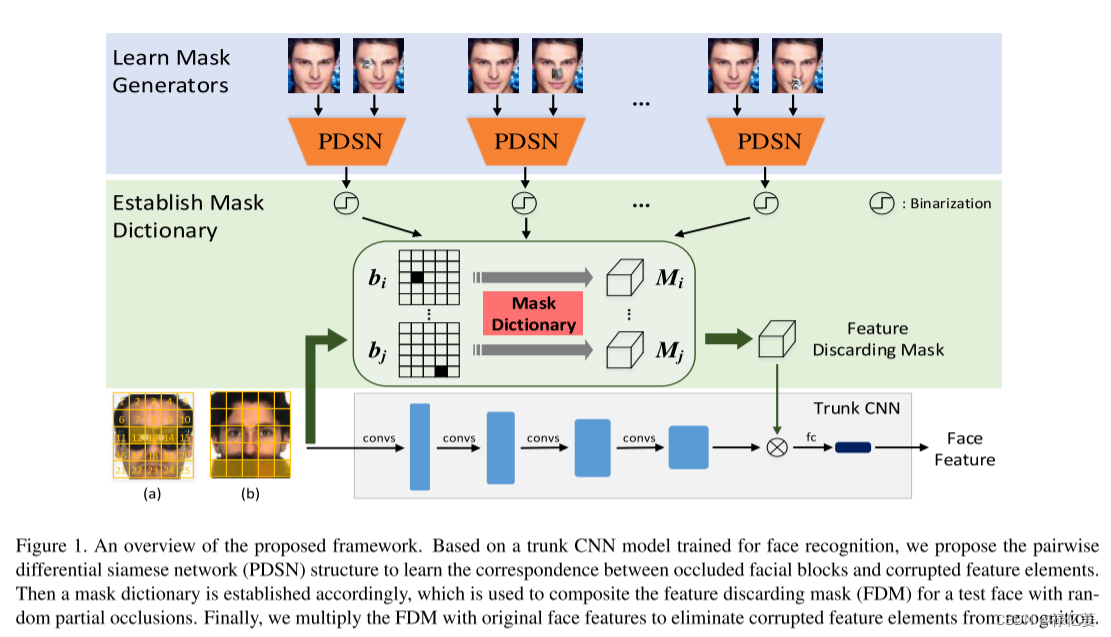
提出了一种掩模学习策略来查找并丢弃识别中损坏的特征元素。首先,使用设计的成对差分孪生网络(PDSN),利用遮挡和无遮挡人脸对的顶部卷积特征之间的差异,可以明确地找到深度 CNN 模型中被遮挡的面部块和损坏的特征元素之间的对应关系,建立掩模字典。该字典的每一项都捕获被遮挡的面部区域和损坏的特征元素之间的对应关系,这被称为特征丢弃掩模(FDM)。当处理具有随机部分遮挡的人脸图像时,通过组合相关字典项来
提出了TPH-YOLOv5。在YOLOv5的基础上,增加了一个预测头来检测不同尺度的目标。然后用Transformer Prediction Heads(TPH)代替原有的预测头,探索自注意机制的预测潜力。还集成了卷积块注意力模型(CBAM),用来发现密集对象场景中的注意力区域。为了实现所提出的TPH-YOLOv 5的更多改进,提供了一些有用的策略,如数据增强,多尺度测试,多模型集成和使用额外的分

MTCNN模型训练输入的所有图像都是正样本(戴口罩的照片),没有负样本作为模型输入。在后续的识别任务模块中,导入MTCNN模型检测结果,对特征点进行编码比较进行识别。
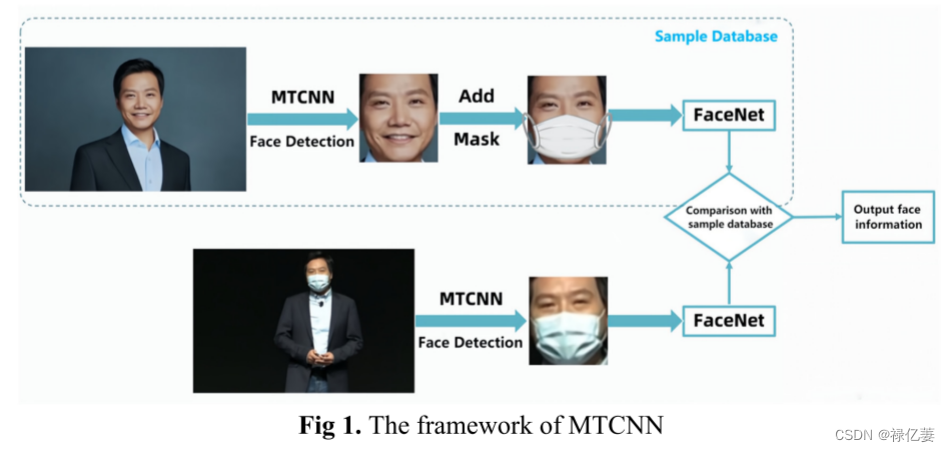
MTCNN模型训练输入的所有图像都是正样本(戴口罩的照片),没有负样本作为模型输入。在后续的识别任务模块中,导入MTCNN模型检测结果,对特征点进行编码比较进行识别。
提出了一种掩模学习策略来查找并丢弃识别中损坏的特征元素。首先,使用设计的成对差分孪生网络(PDSN),利用遮挡和无遮挡人脸对的顶部卷积特征之间的差异,可以明确地找到深度 CNN 模型中被遮挡的面部块和损坏的特征元素之间的对应关系,建立掩模字典。该字典的每一项都捕获被遮挡的面部区域和损坏的特征元素之间的对应关系,这被称为特征丢弃掩模(FDM)。当处理具有随机部分遮挡的人脸图像时,通过组合相关字典项来
本文通过补丁重建的代理任务来初始化模型参数,并观察到 ViT 主干网表现出改进的训练稳定性和令人满意的人脸识别性能。 除了训练稳定性之外,还提出了两种基于提示的策略,将整体和蒙面人脸识别集成在一个框架中,即 FaceT。

所提出的方法Latent-OFER可以检测遮挡,将面部被遮挡的部分恢复为未被遮挡的部分,并识别它们,从而提高 FER 准确性。
