




- @qq_44154915
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
值传递:调用方法时,Java 会将实参的值复制一份,传给形参。对于基本类型,这个“值”就是数据本身;对于引用类型,这个“值”则是对象在堆上的引用(地址)的副本。核心结论无论是基本类型还是引用类型,Java 方法拿到的都是值的拷贝,而不是实参变量本身。
本文围绕“除法运算”这一典型场景,系统介绍 Java 中方法定义、运行时异常(Unchecked Exception)与受检异常(Checked Exception)的使用,以及异常捕获的标准模式与最佳实践,帮助读者在保持代码简洁的同时,提升健壮性和可维护性。Java 仅支持值传递,无论基本类型还是引用类型,方法接收到的都是值的副本。运行时异常(Unchecked)无需声明;若不捕获,将导致程序中
通常在一些竞赛或项目中,baseline就是指能够顺利完成数据预处理、基础的特征工程、模型建立以及结果输出与评价,然后通过深入进行数据处理、特征提取、模型调参与模型提升或融合,使得baseline可以得到改进。baseline这个概念是作为算法提升的参照物而存在的,相当于一个基础模型,可以以此为基准来比较对模型的改进是否有效。所以这个没有明确的指代,改进后的模型也可以作为后续模型的baseline
多源异构定位路径数据的高效融合方法是指在定位系统中,通过整合来自不同源头和不同类型的数据,提高定位路径的准确性和可靠性的方法。这样的系统可能包括GPS、Wi-Fi、蓝牙、惯性传感器等多种传感器和数据源,通过合理融合这些数据,可以更好地解决定位路径中的问题,如误差、不稳定性等。总的来说,高效融合方法需要综合考虑多种因素,包括数据质量、时空关系、传感器性能等,以实现对多源异构数据的合理整合,提高定位路
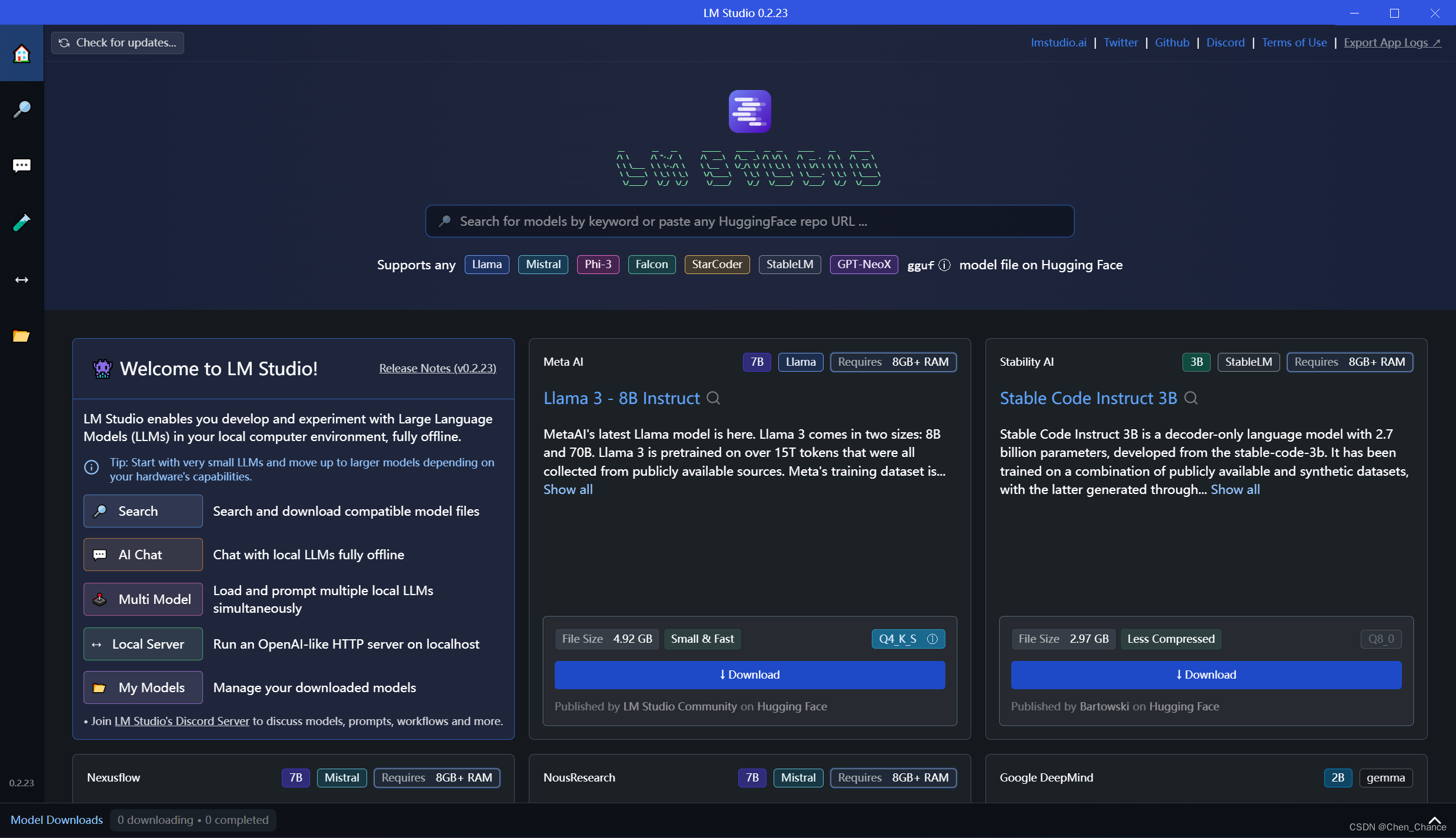
LM Studio是一款革命性的桌面应用程序,它允许用户在自己的计算机上本地运行、管理和部署大型语言模型。这款软件的目标是让大型语言模型更加亲民,让它们的力量可以被更广泛地利用。LM Studio的出现,极大地降低了使用大型语言模型的门槛。无论是研究人员、开发者还是普通用户,都可以利用这款工具来发挥语言模型的潜力。随着人工智能技术的不断进步,LM Studio有望成为本地部署和管理大型语言模型的标
1. CNN(Convolutional Neural Network):应用领域: 主要用于图像处理任务,如图像分类、目标检测和图像分割。特点: 使用卷积层来检测图像中的空间模式和特征,通过池化层降低维度,最终通过全连接层进行分类。2. RNN(Recurrent Neural Network):应用领域: 适用于序列数据,例如时间序列、自然语言处理任务。特点: 具有循环连接,能够捕捉序列中的长

换句话说,它关注的是所有被预测为正类样本中,有多少是正确的。F1值和准确率提供了一个综合考虑精确率和召回率的视角,帮助我们全面评估模型的性能。召回率,也称为真正例率或灵敏度,衡量的是所有实际为正类的样本中,有多少被模型正确预测。准确率是最直观的性能指标,它衡量的是模型正确预测的样本数占总样本数的比例。通过理解这些指标,我们可以更好地评估和选择适合特定任务的机器学习模型,从而在实际应用中获得最佳的性
定义神经网络模型是训练过程中的第一步。神经网络由多个层(如输入层、隐藏层和输出层)组成,每一层包含多个神经元。每个神经元接收来自上一层的输入,并通过激活函数将其转化为输出,传递给下一层。输入层:接收输入特征。隐藏层:进行数据处理和特征转换。隐藏层的神经元个数通常是一个超参数。输出层:输出结果,通常用于分类任务(如Softmax)或回归任务(如线性回归)。常见的神经网络框架包括 TensorFlow

在大模型或者人工智能模型的语境中,字母"B"通常代表“Billion”,即“十亿”。这是用来量度模型中参数的数量。例如,GPT-3模型有175B个参数,这里的“175B”就是表示该模型有1750亿个参数。这样的参数数量是用来衡量模型的复杂度和其处理信息的能力。更多的参数通常意味着模型可以更好地理解和生成更复杂、更自然的语言。
LM Studio是一款革命性的桌面应用程序,它允许用户在自己的计算机上本地运行、管理和部署大型语言模型。这款软件的目标是让大型语言模型更加亲民,让它们的力量可以被更广泛地利用。LM Studio的出现,极大地降低了使用大型语言模型的门槛。无论是研究人员、开发者还是普通用户,都可以利用这款工具来发挥语言模型的潜力。随着人工智能技术的不断进步,LM Studio有望成为本地部署和管理大型语言模型的标