




- @qq_43907505
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
FunASR如何区分说话人并语音识别,语音识别,区分角色ASR,开源的可内网部署的ASR
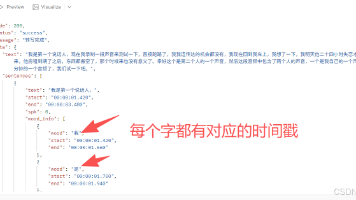
这篇文章主要测试了通过源码编译FunASR的GPU版本语音识别的速度和资源消耗情况。文章真实记录了在单卡和多卡情况下的GPU版本的FunASR的性能情况。
摘要: 开发了一套支持离线的语音转写与声纹识别系统,适用于对数据安全要求严格的场景。系统基于开源ASR和声纹模型(seaco-paraformer、cam++等),支持Windows、MacOS及国产操作系统(如欧拉),提供声纹注册、识别、转写等功能。采用前后端分离架构(FastAPI+前端三剑客),数据存储于MySQL,适用于会议记录、通话质检等场景。目前项目未开源,可通过指定渠道获取演示视频及
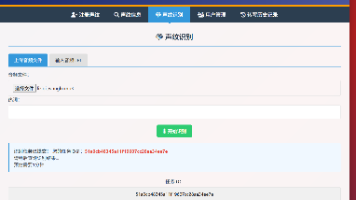
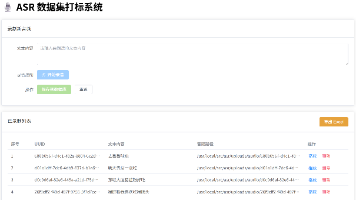
摘要 本文介绍了一个ASR(自动语音识别)数据集采集系统的开发与部署方案。该系统旨在解决传统数据采集过程中音频与文本标签不匹配的问题,通过云端部署实现多人协作采集,提高数据质量和采集效率。系统采用前后端分离架构:后端使用SpringBoot(JDK21),前端使用Vue,配合Nginx作为Web服务器和反向代理,MySQL存储数据并支持Excel导出。 部署过程详细说明了JDK21、MySQL和N
基于funasr实现的可以分离一条录音中不同的说话人的声音,并且支持进行合成相同说话人的声音为一条音频,同时支持视频切片处理。

不小心提交了敏感数据到github或gitee上的解决方法
这篇文章主要讲述了如何利用阿里开源的FunASR工具来训练一个方言ASR模型。其中讲到了如何准备数据,如何设置参数,如何训练,如何评估。
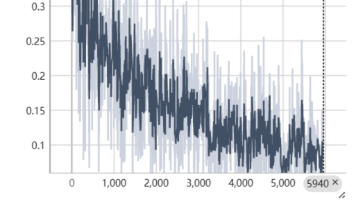
这是一个国内大厂开源的ASR模型,这篇文章主要讲述如何微调SenseVoice和Paraformer模型使得可以准确识别专业名词。
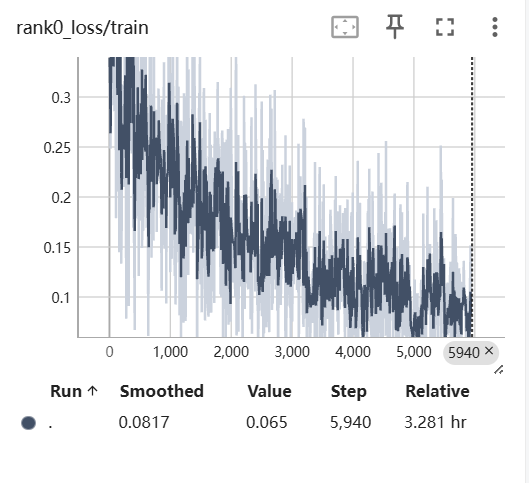
针对某些新的词汇,开源的ASR模型都无法识别,那么这个时候,我们就需要使用专业词汇进行微调了,这篇文章将会告诉你如果微调ASR模型,提升模型对专业名词识别的准确率。
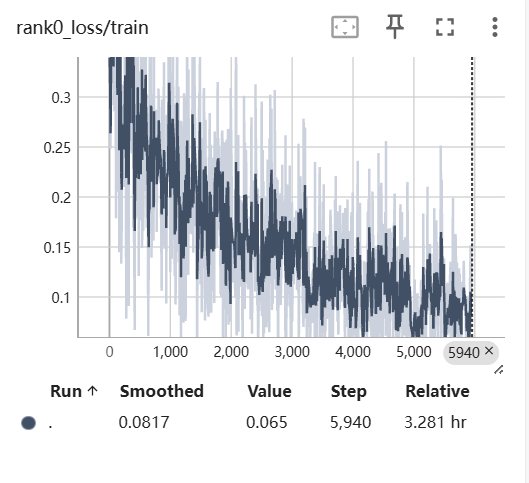
我们在处理一段长音频时包含了多个人的声音,我们想要提取其中某个人的声音,那么我们该如何办呢?如果你会音频处理软件,比如AU,那么你可以使用它来处理,但是这要人工处理几条音频还能接受,如果是处理成千上万条音频呢,我们就必须要借助计算机来处理了。那么本篇文章主要记录我开发的一款可以根据音频中不同的说话人的声音来切分音频片段的软件。
