- @qq_43775680
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
介绍多模态机器学习对齐方向内容
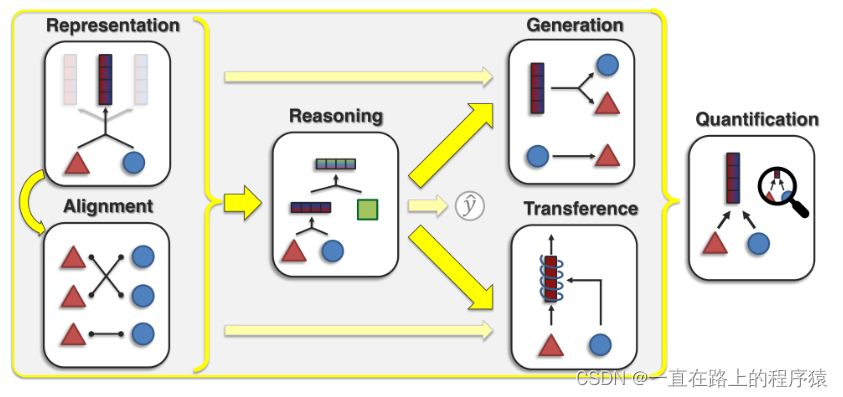
介绍多模态机器学习对齐方向内容
周志华机器学习线性模型
1.本文贡献(1)提出prompt tuning,并在大型语言模型领域展示其与model tuning(fine tuning)的竞争力;(2)减少了许多设计选择,显示质量和鲁棒性随着规模的增加而提高。(3)在域转移问题上,显示prompt tuning优于model tuning。(4)提出“prompt ensembling”,并展示其有效性。2.Prompt tuning在GPT-3中,提示
公式(3)是时间拆分误差(Temporal Difference Error, TD Error)的数学表达式,常用于强化学习(Reinforcement Learning)中的值函数更新(如 TD-Learning 或 TD(λ) 算法)。详细解释如下:以一个例子来理解TD ErrorGRPO对PPO的改进如下:1)消除值函数,以组相对的方式计算优势(①为一个Prompt生成多个输出序列,②为这

1.本文贡献(1)提出prompt tuning,并在大型语言模型领域展示其与model tuning(fine tuning)的竞争力;(2)减少了许多设计选择,显示质量和鲁棒性随着规模的增加而提高。(3)在域转移问题上,显示prompt tuning优于model tuning。(4)提出“prompt ensembling”,并展示其有效性。2.Prompt tuning在GPT-3中,提示
本篇文章重点关注图像和文本信息的对齐工作,在MVSA-S和MVSA-M数据集上达到了SOTA
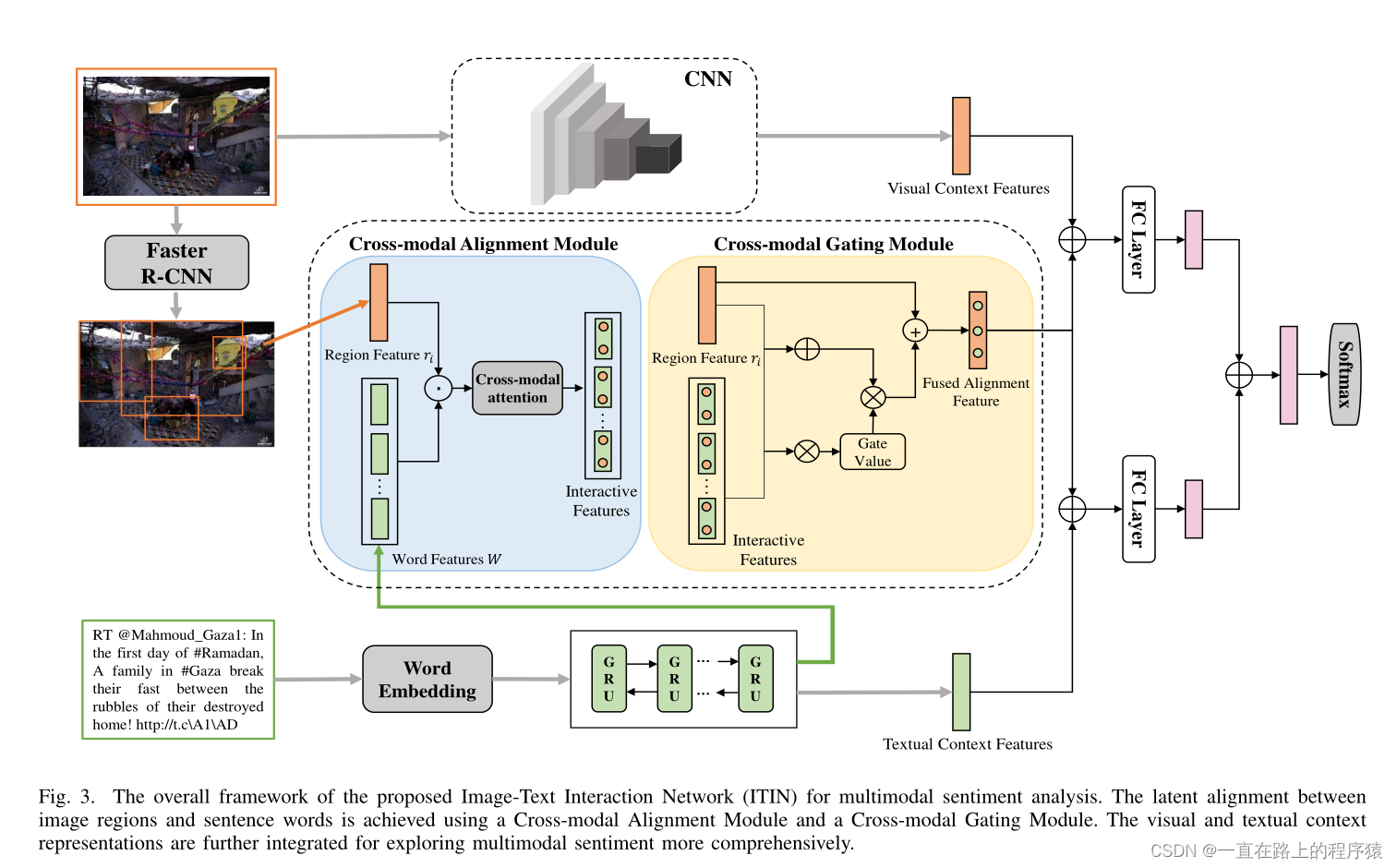
机器学习中的语义信息理解内容