




- @qq_43688472
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
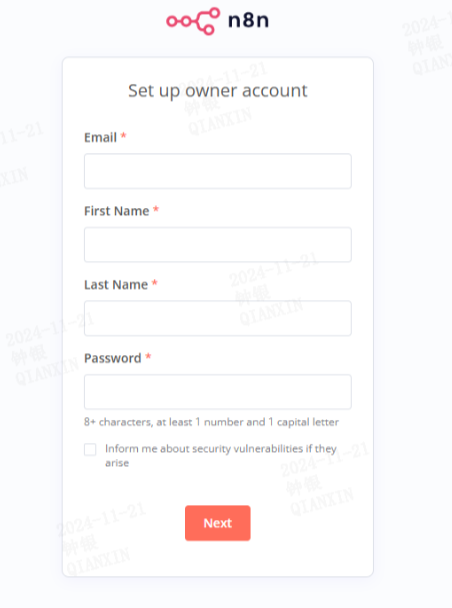
n8n 是一个开源的低代码自动化工作流工具,允许用户通过可视化界面连接不同的应用程序和服务,实现任务自动化。5.更换docker镜像源新建或修改 /etc/docker/daemon.json 文件。2、初次访问http://localhost:5678/,需要填写信息。1、执行以下命令可部署n8n,(版本1.8.2)【下载较慢】
一:存储1.RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。2.DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。二:计算rdd...
复制数据库(本地到阿里云)
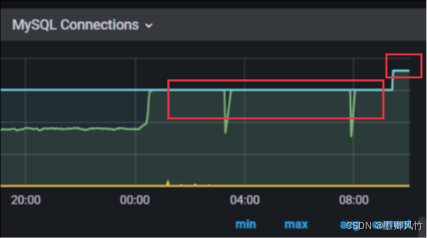
当MySQL数据库主库连接数已满且无法释放,且无法进行主从切换时,需要通过操作系统层面的干预来解决问题。通过杀死无用连接、重启MySQL服务、调整数据库连接数等手段,可以恢复数据库的正常运行。在长期运维中,需要优化应用程序的连接管理、监控数据库性能,并做好数据库的容量规划和故障恢复预案,以确保系统的高可用性和稳定性。
想要删除Atlas元数据,Atlas组件默认是逻辑删除,但是我们想要进行物理删除。在Apache Atlas中,有没有办法在启用硬删除后删除/清除软删除的实体?3、调用AtlasAPI接口进行删除。如何清除软删除的实体。
增量导出Ø 应用场景:将Hive表中的增量记录以及有修改的记录同步到目标表中。Ø 实现逻辑:增量导出(insert模式)HQL示例:insert overwritedirectory ‘/user/root/export/test’ \row format delimited fields terminated by ‘,’ \STORED AS textfile select F1,F2,F3
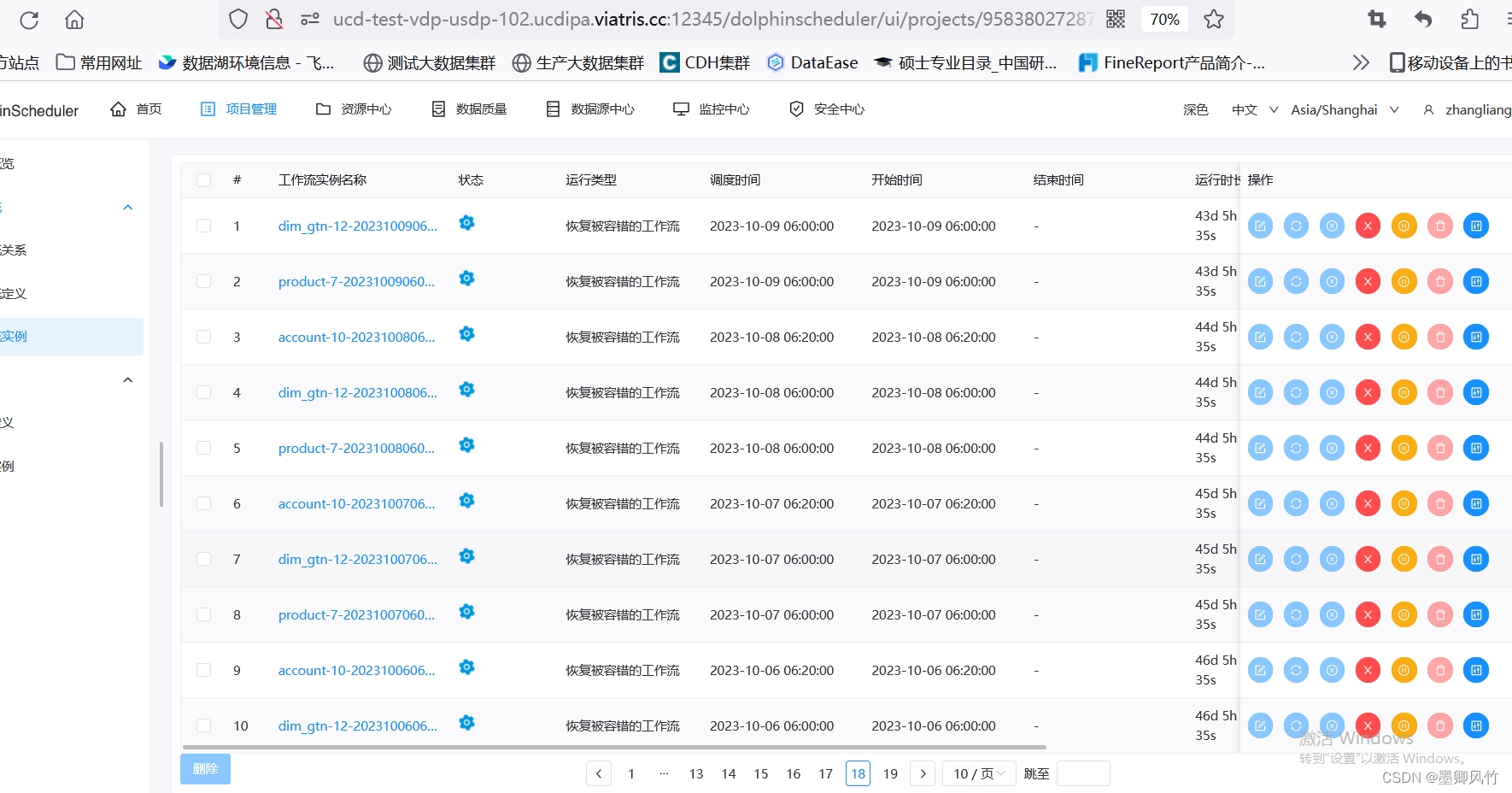
其实对于dolphinscheduler的性能是下降的,比如页面会出现打不开,卡顿现象。这么多的任务没有结束,会涉及很多问题的,系统的数据盘会不断入职日志,数据量很大,目前是通过数据库更改任务状态解决的。11 - 等待依赖项完成。
当MySQL数据库主库连接数已满且无法释放,且无法进行主从切换时,需要通过操作系统层面的干预来解决问题。通过杀死无用连接、重启MySQL服务、调整数据库连接数等手段,可以恢复数据库的正常运行。在长期运维中,需要优化应用程序的连接管理、监控数据库性能,并做好数据库的容量规划和故障恢复预案,以确保系统的高可用性和稳定性。
复制数据库(本地到阿里云)
Doris之导入 Json 格式数据
