




- @qq_43437453
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
论文地址:https://arxiv.org/pdf/2207.09603。
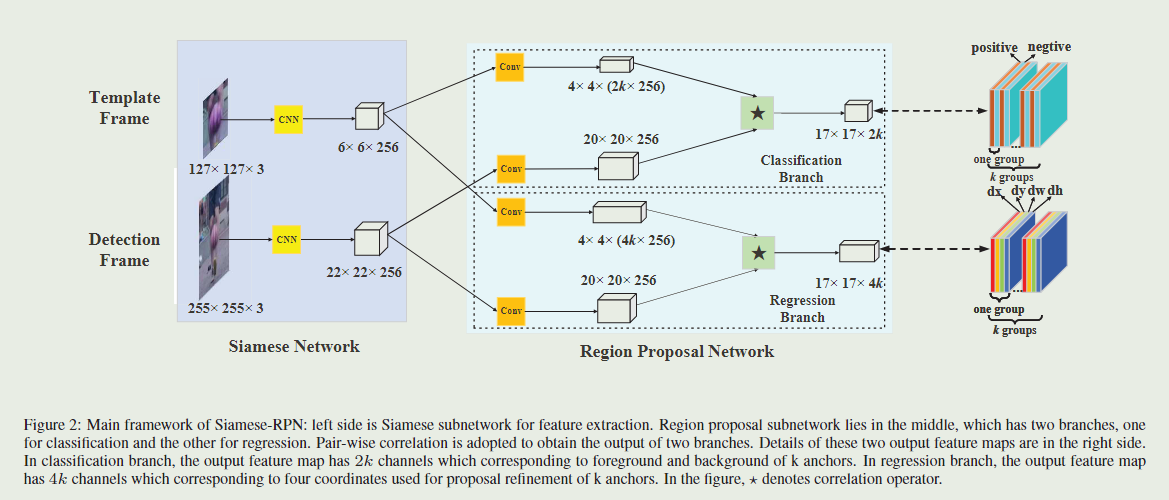
主要讲述目前大部分深度学习算法无法达到高速和准确同时兼顾,本文的SiamRPN利用大量训练图片实现端对端的离线训练,通过孪生网络进行特征提取,RPN网络进行分类和回归操作。在实际跟踪阶段,可以视为单样本目标检测过程(one-shot detection),我们可以预先计算Siamese子网络的模板分支,并将相关层表示为琐屑卷积层来进行在线跟踪。通过改进方案,可以摒弃传统的多尺度测试和在线微调。
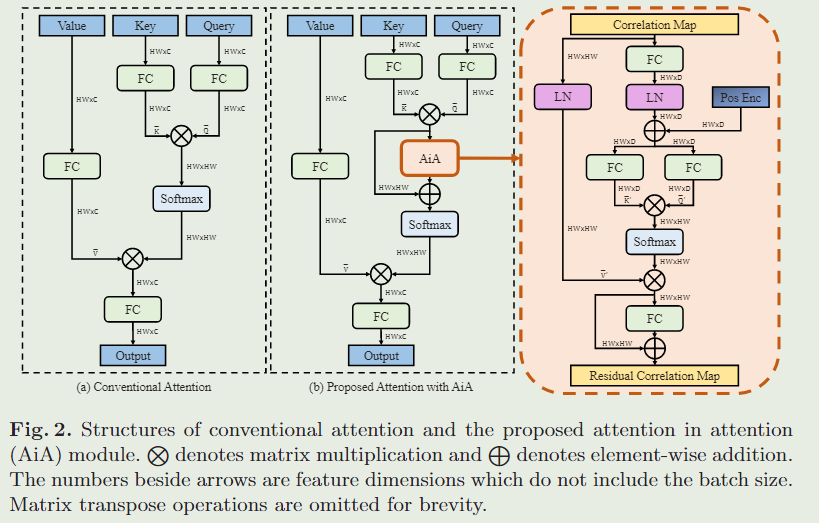
本文主要介绍了基于Transformer的单目标跟踪方法,对这些方法进行了分类、分析、评估和比较,并提出了未来的研究方向。具体来说,本文介绍了Transformer的基本原理和相关知识,然后介绍了基于CNN-Transformer、One-stream One-stage fully-Transformer、Two-stream Two-stage fully-Transformer等不同架构的跟
本文主要介绍了基于Transformer的单目标跟踪方法,对这些方法进行了分类、分析、评估和比较,并提出了未来的研究方向。具体来说,本文介绍了Transformer的基本原理和相关知识,然后介绍了基于CNN-Transformer、One-stream One-stage fully-Transformer、Two-stream Two-stage fully-Transformer等不同架构的跟

这篇论文的贡献是对计算机视觉中注意力机制进行了全面的综述和分析,并提供了以下方面的贡献:综上所述,这篇论文的贡献是对注意力机制在计算机视觉领域中的理解和应用提供了深入的探讨和分析,有助于指导注意力机制在实际应用中的使用和改进。这篇论文的创新点在于提供了一种全面的视角来理解计算机视觉中的注意力机制。它综述了计算机视觉领域中最常用的不同类型的注意力机制,并深入探讨了它们的优缺点、应用和局限性。此外,该