




- @qq_42947060
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
jquerytimers-提供3个函式:everyTime(时间间隔,[计算器名称],函式名称,[次数限制],[等待函式程序完成])//每1s执行函数test()//1s=10$('body').everyTime('1s','A',test,5);//计时器名称为A最多执行5次//每1s执行一次,执行无数次(默认为0),若抵达时间,函数还未执行完毕,则等待。$('body').everyTime
本次学习及其硬核,从sora的技术报告研读,到大咖交流,然后对sora可能实现路径的猜想交流,和开源资料分享。整体脉络非常清晰,本人只是AI技术的爱好者,主职算法不涉及AIGC的内容,可以说是纯小白,但这段时间的学习,让我基本摸清了文生视频的发展路径,了解到了sora为什么能横空出世,只是在这条路径中自己有太多不了解的地方,需要花时间去昂实相关基础。后续会一点一点补齐相关知识,用一些项目练习,相关

在强化学习中,智能体的目标是学习一个策略,这个策略高速它在特定状态下应该采取什么行动,从而最大化长期积累奖励。就是基于策略方法中的核心算法。πa∣s;θθθ即:如果某个动作带来了好的结果,我们就提高在相应状态下选择这个动作的概率;如果结果不好,我们就降低这个概率。
Q-learning是一种无模型的强化学习方法,通过试错学习最优策略。其核心是贝尔曼方程,用Q表记录状态-动作价值,通过时序差分更新:Q(s,a) = Q(s,a) + α[r + γmaxQ(s',a') - Q(s,a)]。例子展示了一个两状态两动作系统的Q值迭代过程,通过即时奖励和折扣因子逐步优化策略。这种方法使智能体能在未知环境中通过探索积累经验,最终形成最优行动策略。
Q-learning是一种无模型的强化学习方法,通过试错学习最优策略。其核心是贝尔曼方程,用Q表记录状态-动作价值,通过时序差分更新:Q(s,a) = Q(s,a) + α[r + γmaxQ(s',a') - Q(s,a)]。例子展示了一个两状态两动作系统的Q值迭代过程,通过即时奖励和折扣因子逐步优化策略。这种方法使智能体能在未知环境中通过探索积累经验,最终形成最优行动策略。
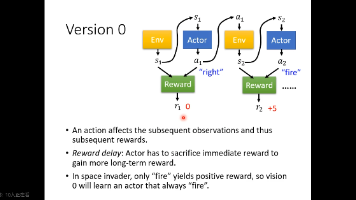
讨论的问题是一个。通过感知所处环境的,这样在交互中学习的方式被称为强化学习。智能体基于当前时刻从环境获取的状态,来决定采取什么动作。环境基于智能体的动作发生状态的改变,并给智能体一个奖励【可以是负的】,最终是为了获取所有奖励和,即收益的最大。
量化回测是金融领域中一种用于评估和验证交易策略的方法。它通过历史市场数据模拟交易策略的表现,为投资者提供了一种客观、系统化的手段,以便更好地理解策略的优势和劣势。

python 列表使用问题
什么是FastAPI高性能的python的web框架使用ASGI为引擎pip install fastapipip install uvicornhttp使用1.1协议FastAPI体量很小,需要自己安装一些扩展插件丰富功能如:jinja2,websocket等例子1-与前端使用http协议进行交互main.pyfrom fastapi import FastAPI#主类from starlett