




- @qq_42495986
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
想象运行一个Python程序,就像在和一个“机器人”对话。那么python的三个标准“流”对象(sys.stdinsys.stdoutsys.stderr错误信息或警告输出。

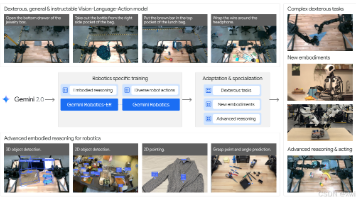
从 Gemini 2.0 到实体机器人Gemini 2.0 的世界知识和推理能力可以通过机器人落地到物理世界。:具身 VLM(Vision-Language Model with Embodiment),在空间理解、轨迹预测、多视图匹配、精确指向等任务上显著提升了现有技术水平。通过新的开源基准ERQA验证了其性能。零样本(Zero-shot)与少样本(Few-shot)适应能力Gemini Rob
正则表达式(Regular expressions,也叫 REs、 regexs 或 regex patterns),本质上是嵌入 Python 内部并通过模块提供的一种微小的、高度专业化的编程语言。使用这种小语言,你可以;这些字符串可能是英文句子、邮箱地址、TeX 命令或任何你喜欢的内容。然后,你可以提出诸如“。你还。正则表达式会被编译成一系列字节码,然后由 C 语言编写的匹配引擎执行。对于高级
要实现字符串的拼接,使用占位符是的一种高效、常用的方式。举个例子,下面是不使用占位符的一种写法,直接使用加号拼接字符串age = 24换成占位符,可以写成age = 24其中%s%d便是占位符,顾名思义,其作用就是替后面的变量站住这个位置字符串后面的%是一个特殊的操作符,该操作符会将后面的变量值,替换掉前面字符串中的占位符。对比两种写法,会发现使用占位符可以将字符串中用到变量集中在一起,方便查找和

Python 的str(字符串)是每次用或其它方式“拼接**”都会创建新的字符串对象**,如果拼很多次,会造成很多临时对象,性能差。因此,(比如几段)用或 f-string 很方便;应用或字符串缓冲()或构建 list 再 join。

Python 的类型提示(Type Hints)是 Python 3.5 引入的一项特性(通过 PEP 484),它允许开发者在代码中标注变量、函数参数和返回值的预期类型。这些提示不会在运行时强制执行(Python 仍是动态类型语言),而是用于静态分析工具(如 mypy、pyright)、IDE(如 PyCharm、VS Code)和代码文档化,帮助及早发现类型错误、提升代码可读性和维护性。

本文提出UAV-VLA系统,通过结合大语言模型和视觉语言模型,实现基于自然语言指令的无人机航线自动生成。系统包含目标提取、目标搜索和动作生成三个模块,利用卫星图像和地理坐标数据,将文本指令转化为可执行的飞行计划。研究建立了包含30张高分辨率卫星图的评估基准UAV-VLPA-nano-30,实验表明系统生成速度比人工快6.5倍,虽然航线长度平均增加21.6%,但大幅提高了任务规划效率。该工作为语言驱

序号1.将大模型的慢思考引入物理具身控制 以前的机器人模型(如RT-2)是“直肠子”,看到画面直接输出动作(端到端),遇到复杂环境(如颜色相近、多个目标)极容易出错。VLA-R1 首创了在具身控制中引入 <think>推理轨迹</think> + <output>7D物理动作</output> 的结构化输出格式。强制机器人“谋定而后动”,先在赛博大脑里用自然语言进行空间消歧和逻辑推演,再将意图降维
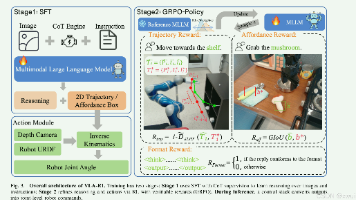
序号1.将大模型的慢思考引入物理具身控制 以前的机器人模型(如RT-2)是“直肠子”,看到画面直接输出动作(端到端),遇到复杂环境(如颜色相近、多个目标)极容易出错。VLA-R1 首创了在具身控制中引入 <think>推理轨迹</think> + <output>7D物理动作</output> 的结构化输出格式。强制机器人“谋定而后动”,先在赛博大脑里用自然语言进行空间消歧和逻辑推演,再将意图降维
序号1.将大模型的慢思考引入物理具身控制 以前的机器人模型(如RT-2)是“直肠子”,看到画面直接输出动作(端到端),遇到复杂环境(如颜色相近、多个目标)极容易出错。VLA-R1 首创了在具身控制中引入 <think>推理轨迹</think> + <output>7D物理动作</output> 的结构化输出格式。强制机器人“谋定而后动”,先在赛博大脑里用自然语言进行空间消歧和逻辑推演,再将意图降维