




- @qq_41797451
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在RTX 3090+Ubuntu 22.04环境下,遇到PyTorch 2.11.0+cu130报"NVIDIA驱动版本过旧"错误。通过升级NVIDIA驱动从535到580.159.03,解决了libnvidia依赖冲突、dpkg held package锁定及Wayland EGL缺失等问题,最终使torch.cuda.is_available()返回True。
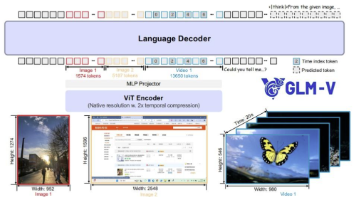
智谱AI与清华大学联合推出新一代视觉语言模型GLM-4.1V-9B-Thinking,在28项评测任务中刷新记录,甚至超越72B级闭源模型。该模型首创"思维链推理机制",支持多模态输入,兼具轻量化部署与超强推理能力。采用三阶段训练策略与多模态统一架构,在复杂推理任务中表现优异。已在GitHub、HuggingFace等平台开源,适用于教育、金融、政务等多领域,成为国产AI的重要
LangChain是一个专为构建大模型应用设计的开发框架,其模块化设计和丰富的工具链让智能体开发更高效。内置Agent模板:快速实现工具调用、多轮对话、记忆管理无缝对接主流大模型:支持OpenAI、ChatGLM、DeepSeek等灵活可扩展:通过Chains组合实现复杂业务逻辑。

Git LFS缺失导致Step-Audio-EditX项目无法拉取模型权重的解决方案。当执行git lfs install时出现git: 'lfs' is not a git command错误,表明系统未安装Git LFS扩展。在Ubuntu下只需三步:1) sudo apt install git-lfs安装工具;2) git lfs install初始化;3) git lfs pull拉取真

本文详细解析了两条关键Docker命令,帮助开发者快速搭建ROS2 Humble开发环境。第一条命令docker run -itd -v /root/home:/root/home --network host --name ros2_humble osrf/ros:humble-desktop创建并运行容器,包含交互模式、数据持久化挂载和主机网络配置。第二条命令docker exec -it r
本文针对Docker在Linux环境下的两大常见问题提供解决方案:1)通过将用户加入docker组解决权限问题,避免频繁使用sudo;2)配置国内镜像加速器解决拉取镜像超时问题。文章详细介绍了配置步骤,包括编辑daemon.json文件和重启服务,并特别处理了通过Snap安装Docker时的特殊情况。最后建议标准化安装方式,为Docker初学者提供完整的环境配置指南,帮助用户顺畅开启容器技术学习之
本文详细解析了两条关键Docker命令,帮助开发者快速搭建ROS2 Humble开发环境。第一条命令docker run -itd -v /root/home:/root/home --network host --name ros2_humble osrf/ros:humble-desktop创建并运行容器,包含交互模式、数据持久化挂载和主机网络配置。第二条命令docker exec -it r
本文详细介绍了在Windows系统下使用Docker快速搭建ROS2 Kilted(2025最新版)开发环境的方法。主要内容包括:通过Docker拉取ROS2镜像、配置容器环境、实现X11 GUI可视化(以小乌龟仿真为例),以及VS Code远程开发连接。该方案具有环境隔离、快速部署和跨平台一致三大优势,5分钟即可完成配置,无需安装双系统。文章还提供了常见问题解决方案和进阶环境保存技巧,是学习RO
本文介绍如何通过Ollama的keep_alive参数优化本地大语言模型部署效率。默认模型5分钟自动卸载导致重复加载损耗性能,可通过API参数(如"24h"或"infinite")或环境变量OLLAMA_KEEP_ALIVE实现模型常驻显存。详细说明Linux系统下systemd服务的配置方法,并提醒注意显存容量与多模型场景的资源管理。该方案可显著减少加载延
阿里通义实验室推出4800亿参数Qwen3-Coder系列AI编程模型,采用混合专家架构(MoE),支持256K上下文并可通过YaRN扩展至100万tokens。该模型在7.5万亿token数据上训练,代码占比70%,具备自主规划、工具调用等智能体能力,刷新开源模型记录。提供Qwen Code、Claude Code等多种集成方案,支持OpenAI兼容API调用。Qwen3-Coder标志着AI编