




- @qq_41771998
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这一点很重要,首先,因为机器学习研究中的模式通常是有人建立了一种技术,其他人找到了使它更好地工作的方法,然后其他人随着时间的推移对其进行调整,同时增加计算以产生比你开始时更好的结果。这是一个自我限制的过程,因为实际上您只能将这么多的计算用于给定的任务。尽管 Midjourney 和 Stable Diffusion 等流行工具使用的扩散模型可能看起来是我们所拥有的最好的,但下一个东西总是会出现——

但是由于很多用户并不是 macOS 用户,所以特此开发了一个浏览器插件方便非 macOS 用户使用 ChatGPT 进行划词翻译。点击浏览器插件列表里的 OpenAI Translator 图标,把获取的 API KEY 填入此插件弹出的配置界面中。如果您每次打开它都遇到权限提示,或者无法执行快捷键划词翻译,请前往。,并输入以下命令(中途可能需要输入密码),然后重启。刷新浏览器页面,即可享受丝滑般
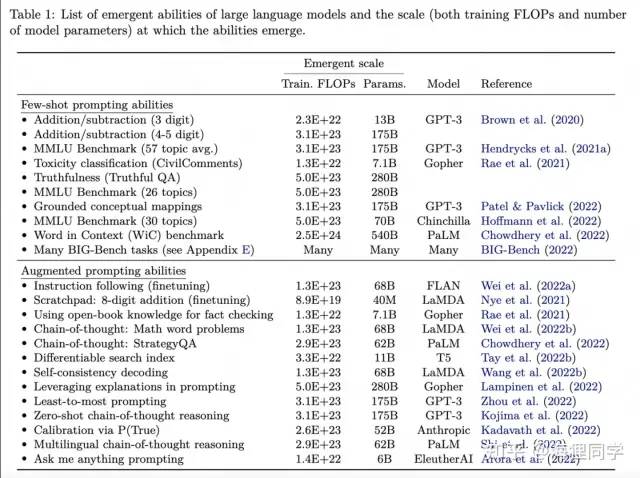
few-shot prompting的emergent主要体现为模型在没有达到一定规模前,得到的表现较为随机,在突破规模的临界点后,表现大幅度提升。虽然本文主要探究模型超过一定规模后出现emergent ability, 但模型仍然有可能通过数据,算法的改进在更小规模出现emergence. 比如在BIG-Bench任务上,LaMDA在137B,GPT-3在175B上出现emergent abil
偶然发现Github上某位大佬开源的DIFY源码注释和解析,目前还处于陆续不断更新地更新过程中,为大佬的专业和开源贡献精神点赞。先收藏链接,后续慢慢学习。相关链接如下:DIFY源码解析

综上所述,GPT是自然语言处理领域中最强大的模型之一,它的出色表现已经使得它在各种应用场景中得到了广泛的应用。

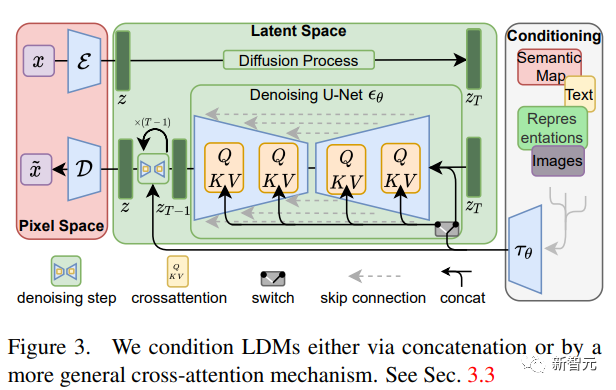
不过图像生成真正进入全民化还要数Stable Diffusion的开源,仅在消费级的GPU上即可运行,用户可以在自己的数据集上进行微调,也不用忍受各大绘画网站为了「安全」设立的各种过滤词表,真正实现了「绘画自由」。通过将图像形成过程分解为自动编码器去噪的顺序应用,扩散模型实现了对图像数据和其他数据的最新合成结果,并且扩散模型的公式能够接受一个引导机制来控制图像生成过程,而不需要重新训练。为了能够在
偶然发现Github上某位大佬开源的DIFY源码注释和解析,目前还处于陆续不断更新地更新过程中,为大佬的专业和开源贡献精神点赞。先收藏链接,后续慢慢学习。相关链接如下:DIFY源码解析
我们需要充分利用ChatGPT的优势和潜力,同时也需要警惕其可能带来的负面影响,采取适当的措施来保障人们的利益和权益,推动人工智能技术的健康发展和应用。技术风险和安全问题:ChatGPT需要依赖计算机系统和网络技术,这可能会带来技术风险和安全问题,如黑客攻击、数据泄露、人工智能算法错误等,这些问题需要加强技术和安全措施来保障人们的安全和权益。对人类智能的替代:随着ChatGPT的发展和应用,它有可

本文使用通俗易懂的语言对BERT模型的原理和实现过程进行简明扼要地介绍,希望能够帮助想深入了解BERT模型的朋友们。
更重要的是,通过在多个时间步链接 Consistency Models 模型的输出,该方法可以提高样本质量,并以更多计算为代价执行零样本数据编辑,类似于扩散模型的迭代优化。前面我们已经提到,OpenAI 的这项研究主要是图像生成方面的,大家或多或少的都听过这项技术,例如最近热门的 Midjourney 和 Stable Diffusion,它们大都采用扩散模型,由于其生成的图片效果惊艳,很多人都将
