




- @qq_41611586
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
咨询 培训 项目
本文将带你从零开始,快速掌握如何将 DeepSeek API 与高效的 Python Web 框架 FastAPI 集成,通过简单易懂的实例,一步步完成 API 服务的搭建,轻松实现人工智能交互接口。
本系列教程共分为三个部分,每部分下又拆分成若干节,每节控制在半小时左右,让你可以有条不紊、循序渐进地完成学习和实操。在这个智能时代,越来越多的工作场景都离不开人工智能的支持。尤其是OpenAI的出现,让人们看到了AI在内容创作、文案撰写、数据分析等方面巨大的潜力。随着你不断深入学习,会逐渐发现OpenAI不仅能减少你日常工作的重复劳动,也能激发更多创意,让工作成果更加出色。如果你对AI的未来充满期
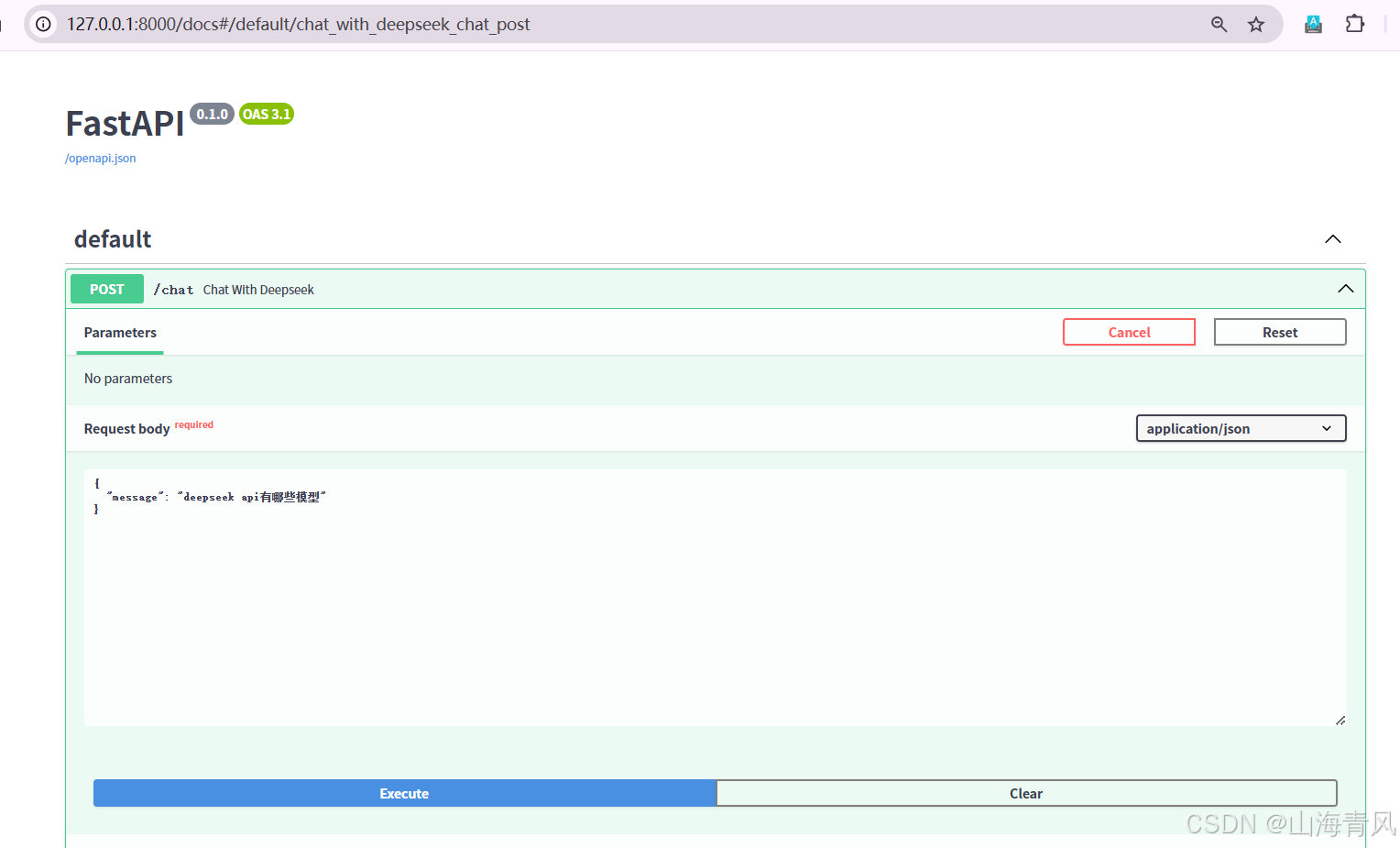
想象一下,你是某家房地产中介公司的数据分析师。你的老板找到你,说:“我们希望用数据来预测房子的合理价格,让买家和卖家都能得到公平的交易。所以,我们需要把文本转换成数值,让模型可以理解。为了更直观地对比三个模型的预测效果,我们可以绘制真实房价 vs. 预测房价的散点图。假设你准备买一套房子,它的价格是 100 万元,你觉得这个价格合理吗?🎯 建议:在你的数据上运行 df.head() 看看转换后的
的思想:找到最经济、最有效的 K 值,而不是无限增加 K。确保 K-Means 不会受到特征数值范围的影响。帮助我们找到最佳的 K 值,使得分群更加合理。,就是把相似的数据自动分成不同的**“组”,如果不同特征的数据范围相差太大,可能导致。在 K-Means 里,我们需要决定。是最常见的聚类算法之一。,可以帮助商家更好地理解客户行为。应用 K-Means 聚类!✅ 通过 K-Means 进行。簇(

当我们训练神经网络时,模型会随着训练轮次(epochs)不断学习,但怎么知道它是否真的在变聪明呢?model.fit(…) 的返回值 history 记录了每一轮训练的准确率和损失。如果 训练准确率高,但测试准确率低,说明模型过拟合了。,包含 60,000 张手写数字(0~9)的图片。测试准确率,表示模型在未见过的测试集上的表现。训练准确率,表示模型在训练集上的表现。如果曲线不断上升,说明模型在学
本文使用的是 train.csv,请下载后将其重命名为 house-prices.csv 方便代码使用。下载本文使用的 house-prices.csv 数据集。,会影响后续机器学习模型的效果。在开始处理数据之前,我们需要。房价数据中,不同的特征有。因此,我们的第一步是。:删除(如果影响不大)(适用于有顺序的类别)(适用于无顺序的类别)(中位数、None)
如果数据集中正常邮件的数量远远多于垃圾邮件,模型可能会倾向于预测所有邮件都是正常邮件,从而得到较高的“假准确率”(即准确率看起来很高,但实际上垃圾邮件检测效果很差)。首先,我们需要加载 Kaggle 上的垃圾邮件数据集。机器学习模型无法直接理解文字,我们需要将。,如垃圾邮件 vs 正常邮件。✅ 添加更多垃圾邮件,提高样本数量。,如房价、温度、工资等。,尝试是否能提高效果。
神经网络 TTS 的输出存在“受约束的随机性”固定随机种子可以获得高度可复现的输出随机性是自然度的重要来源,工程上应按场景取舍这一结论将在后续理解 VITS 与多语言 TTS 策略时反复出现。
【AI产品效果评估指南】本文介绍了如何系统评估AI产品的表现,从核心概念到实践操作。评估聚焦三大指标:质量(准确率、覆盖率)、性能(响应时间、吞吐量)和成本(Token消耗、算力)。通过构建迷你评测器(BGE+DeepSeek R1),演示了自动评估流程:向量检索文档→生成答案→检查关键点命中率(pts/tot)。产品经理需掌握评估方法,用数据驱动决策,在PRD中明确准确率、响应时间等量化指标,为
测试覆盖率是软件质量保障中的重要指标,它衡量了代码中被测试到的部分占整体代码的比例。低覆盖率可能导致问题未被发现,影响产品稳定性。通过OpenAI等AI工具,可以更智能地优化测试覆盖率,定位薄弱环节,生成更多有效的测试用例。以下,我们将结合实际操作,说明如何利用OpenAI提升测试覆盖率,让测试工程师的日常工作更高效。测试覆盖率的常见类型包括:例如,假设你有以下代码片段:如果只测试,那么条件和未被
