




- @qq_41298763
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
huggingface是一个开源社区,它提供了先进的NLP模型,数据集、以及其它便利工具。huggingface提供的模型非常多,但主要的模型为:自回归: GPT2Trasnformer-XLXLNet自编码: BERTALBERTRoBERTaELECTRA自回归模型:预测下一个词,因为使用x获取y叫做回归,所有x预测下一个x称为自回归自编码模型:还原出本身,根据上下为还原出本身的词Seq2Se

在使用vs code连接远程服务器,打开python项目时,发现如下图所示,试了试ctrl + 鼠标左键无法链接跳转至函数内部,对代码开发造成极大影响。随后发现没有选择环境python interpreter,可无论是设置还是vscode右下角都找不到select interpreter。后来发现vs code初次远程连接服务器时,需要在服务器上启用一个拓展,其实就在上图处重新install一下即
什么是vllm?vLLM 是一个高性能的大型语言模型推理引擎,采用创新的内存管理和执行架构,显著提升了大模型推理的速度和效率。它支持高度并发的请求处理,能够同时服务数千名用户,并且兼容多种深度学习框架,方便集成到现有的机器学习流程中。通过一个名为的新型注意力算法来解决传统LLM在生产环境中部署时所遇到的高内存消耗和计算成本的挑战。PagedAttention算法能有效管理注意力机制中的键和值,将它
上图左侧就是欠拟合,右侧就是过拟合。一个由于模型太过于简单难以拟合所有数据,一个模型记住了所有的训练数据,但泛化误差却很大(因为我们需要的模型并不是记住所有的训练数据,而是可以帮我们进行预测未知features的label)。如上图所示,模型容量就是模型复杂度,低容量模型难以拟合所有的数据(欠拟合),高容量的模型可以记住所有的训练数据(过拟合)。甚至于,为了追求低的泛化误差,甚至可以使得模型过拟合

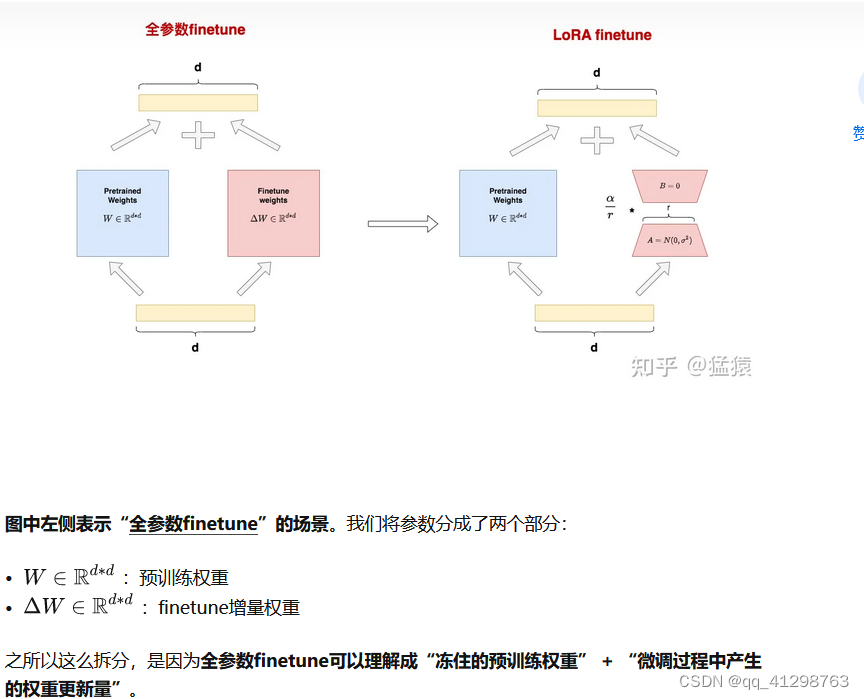
正常神经网络:输入x -> 全连接层(w) -> 输出y,训练时输入x,y数据来更新参数w,使得loss最小,w达到最优。但在大模型中,参数量都是几十几百亿的没计算量极大,在进行梯度计算时,内存硬件都无法支持。LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。r + d*r,并且r
在使用vs code连接远程服务器,打开python项目时,发现如下图所示,试了试ctrl + 鼠标左键无法链接跳转至函数内部,对代码开发造成极大影响。随后发现没有选择环境python interpreter,可无论是设置还是vscode右下角都找不到select interpreter。后来发现vs code初次远程连接服务器时,需要在服务器上启用一个拓展,其实就在上图处重新install一下即
上述是生成一个简单数据集代码,最后的features的shape为torch.Size([1000, 2]),labels的shape为torch.Size([1000, 1])。注意数据集的所有数据都是tensor张量,用于在gpu上计算.上述为调用torch.utils.data中的Dataset和DataLoader类应用于自己的数据集,来训练模型。上述为训练模型时的数据增强代码(主要是裁剪

正常神经网络:输入x -> 全连接层(w) -> 输出y,训练时输入x,y数据来更新参数w,使得loss最小,w达到最优。但在大模型中,参数量都是几十几百亿的没计算量极大,在进行梯度计算时,内存硬件都无法支持。LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。r + d*r,并且r
无论是流式还是非流式输出,vllm的LLM函数创建的模型对象通常以同步的方式工作,处理多并发情况时只能以队列形式一个个输出。对于流式输出,它也可以逐步返回数据给前端,但这是假流式,因为后端以及把所有的文本都输出了,然后我们又把文本一个个传给前端。:异步引擎同样可以支持流式和非流式输出,但它允许你以非阻塞的方式处理这些输出。大模型的流式输出(Streaming Output)和非流式输出(Non-s

但每次迭代中只使用一个样本计算梯度,因此每次迭代的梯度都是有噪声的,毕竟不是所有样本的均值,所以下降(下山)会走一点弯路,但总体因为总的迭代次数很多,所以随机梯度下降法最终会收敛到最优解 ,还是划得来的。我们可以其看作一个下山的过程:对于梯度下降而已,是找到了最优的下山路径,所有它的曲线比较直,而对于随机梯度下降,它因为随机选一个样本ti来近似f(x)——所有样本的损失平均,所以找的并不是最优的下
