- @qq_41200212
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
软件故障定位(SFL)是软件调试的核心技术,对提升软件开发与维护效率至关重要。大语言模型(LLMs)开创了无需测试用例的软件故障定位新范式,但这类模型因计算成本极高、依赖外部 API 处理代码引发隐私安全问题,严重限制了实际应用。这些不足表明,亟需一种轻量化、隐私保护、易部署的替代方案,取代基于大语言模型的软件故障定位方法。
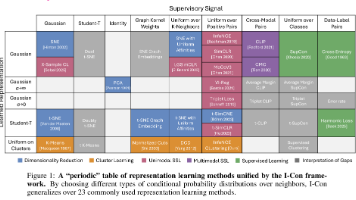
随着表征学习领域的快速发展,各类损失函数层出不穷,用于解决不同类别的问题。本文提出了一种统一的信息论方程——信息对比学习框架(I-Con),可泛化机器学习中的多种现代损失函数。该框架表明,多个主要类别的机器学习方法本质上是在最小化两个条件分布(监督分布与学习到的表征分布)之间的积分KL散度。这一视角揭示了聚类、谱方法、降维、对比学习和监督学习等方法背后隐含的信息几何结构。通过该框架,我们不仅能建立
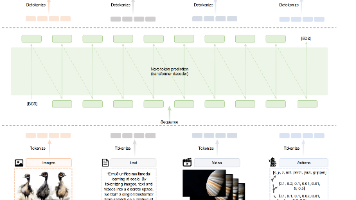
北京AI研究院团队提出Emu3多模态模型家族,仅通过下一token预测统一处理文本、图像和视频等模态。该研究突破了传统多模态学习依赖扩散模型或组合架构的局限,证明单纯的自回归框架可实现感知与生成的统一。Emu3采用视觉分词器将多模态数据转化为离散token序列,基于Transformer架构进行端到端训练。实验表明,其性能与特定任务模型相当,支持高保真视频生成、视觉语言交互及机器人操作建模。研究通
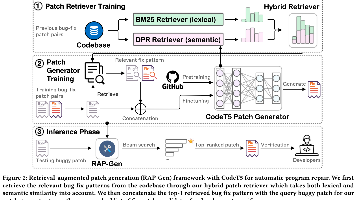
自动程序修复(APR)对于减少开发人员的手动调试工作并提高软件可靠性至关重要。虽然传统的基于搜索的技术通常依赖于启发式规则或冗余假设来挖掘修复模式,但近年来,基于深度学习 (DL) 的方法的激增,以数据驱动的方式自动化程序修复过程。然而,它们的性能通常受到一组固定参数的限制,无法对 APR 的高度复杂搜索空间进行建模。为了减轻参数模型的负担,在这项工作中,我们提出了一种新颖的检索增强补丁生成框架(
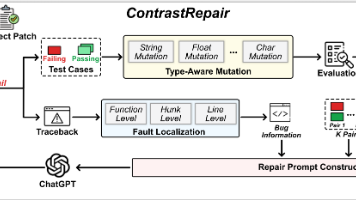
自动化程序修复(APR)旨在自动生成补丁修复软件漏洞,基于大语言模型(LLM)的对话式 APR 是当前研究热点,但其效果高度依赖反馈信息质量。本文提出,一种新型的基于对话的 APR 方法,通过为 LLM 提供对比测试用例对(失败测试用例 + 高度相似的通过测试用例)补充正负反馈,精准隔离漏洞根因,提升修复效果。该方法以 ChatGPT 为基础模型,通过最小化失败与通过测试用例的差异构建对比对,若无
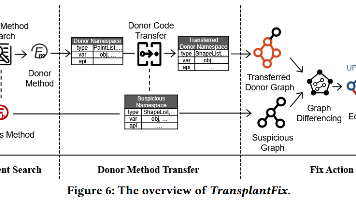
自动程序修复 (APR) 有望帮助手动调试活动。经过十多年的发展,人们提出了广泛的 APR 技术,并在一组真实的错误数据集上进行了评估。然而,尽管越来越多的错误得到了正确修复,但我们观察到,近年来通过 APR 技术修复的新错误的增长已经遇到了瓶颈。在这项工作中,我们提出 TransplantFix 来探索解决复杂错误的可能性,TransplantFix 是一种新颖的 APR 技术,利用捐赠者方法中
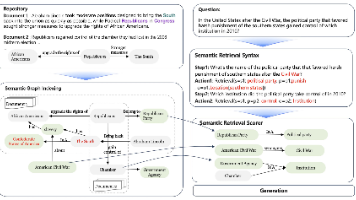
KAG框架提出了一种知识增强生成方法,通过在RAG技术中集成知识图谱的语义推理能力,显著提升了专业领域问答的准确性。该框架采用语义图索引(结合稀疏符号与稠密向量)、语义解析与推理(将问题转化为逻辑形式)、语义检索三大模块,解决了传统RAG方法依赖相似度检索和共现生成的局限性。实验表明,KAG在多跳QA任务中优于现有RAG方法,并在电子政务场景中验证了其专业性能提升。该项目已开源,支持OpenSPG
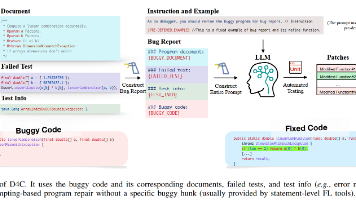
本文提出D4C框架,通过目标对齐优化大语言模型(LLM)在自动程序修复(APR)中的应用。研究发现现有方法存在两个关键问题:1)解码器LLMs的预测目标与填充式修复方法不一致;2)传统错误定位-修复流程限制LLMs发挥预训练能力。D4C将修复任务重构为程序精炼问题,让LLMs直接生成完整函数而非局部补丁,并与训练目标对齐。实验表明,D4C在Defects4J数据集上修复180个缺陷,性能超越当前最
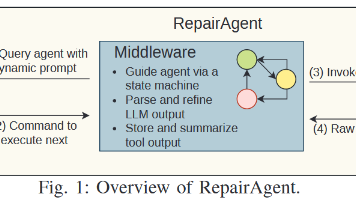
自动程序修复已成为一种强大的技术,可以减轻软件错误对系统可靠性和用户体验的影响。本文介绍了 RepairAgent,这是第一个通过基于大语言模型 (LLM) 的自治代理来解决程序修复挑战的工作。现有的基于深度学习的方法通过固定提示或固定反馈循环来提示模型,而本文的工作将 LLM 视为能够自主规划和执行操作以通过调用合适的工具来修复错误的代理。RepairAgent 自由地交叉收集有关错误的信息、收
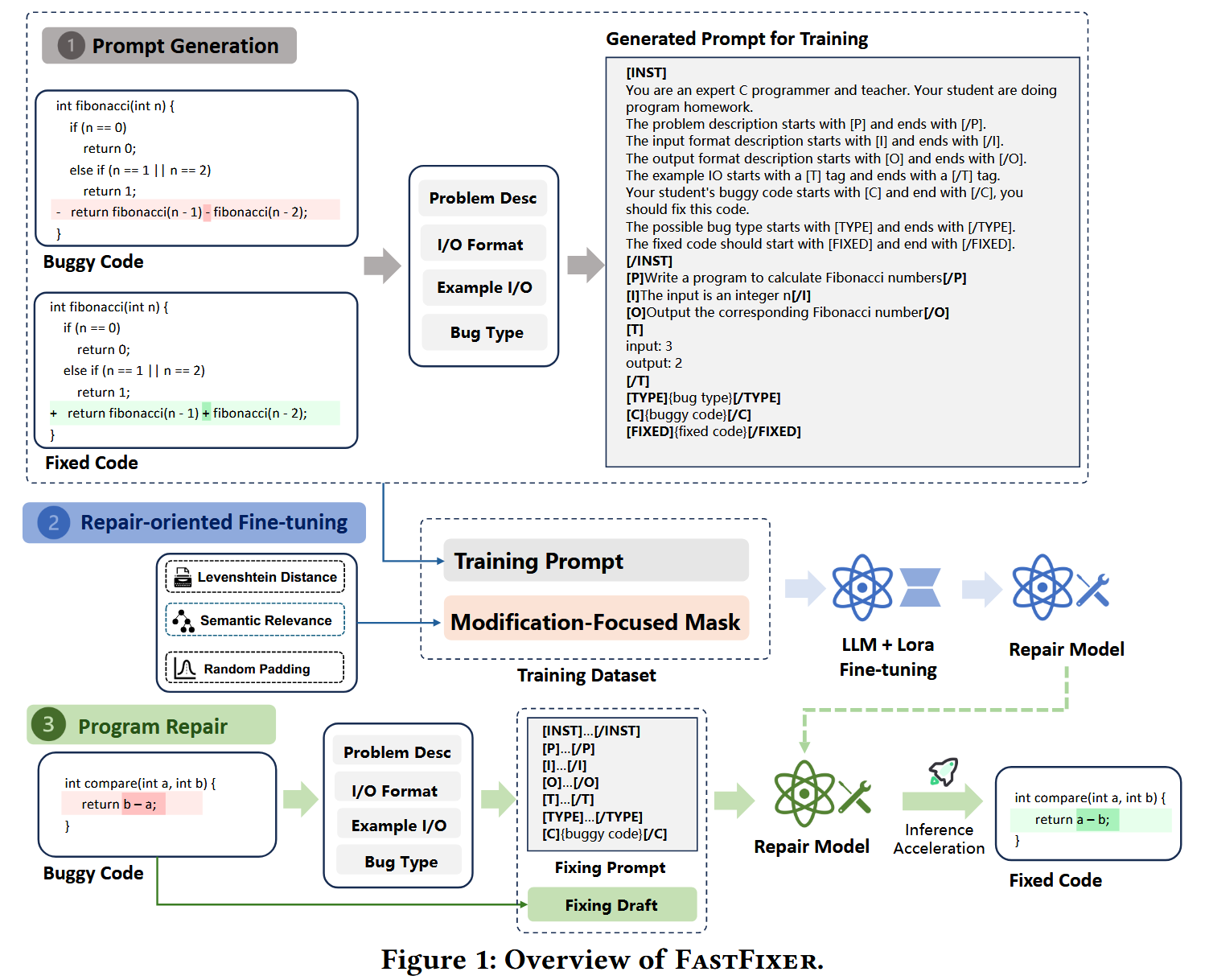
为学生的编程作业提供个性化和及时的反馈对于编程教育至关重要。自动程序修复 (APR) 技术已被用于修复编程作业中的错误,其中基于大型语言模型 (LLM) 的方法已显示出可喜的结果。鉴于在高级编程作业中识别和修复错误的复杂性日益增加,当前 APR 的微调策略不足以指导 LLM 在生成修复过程中识别错误并进行准确编辑。此外,LLM 采用的自回归解码方法可能会阻碍修复的效率,从而阻碍提供及时反馈的能力