- @qq_40943760
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
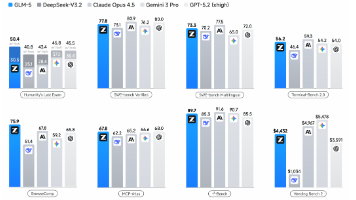
GLM-5,在线跨阶段蒸馏与Agentic工程
HealthGPT 旨在解决医学领域中视觉理解(Comprehension)与生成(Generation)任务之间的冲突,通过构建高质量的数据集和引入创新的架构,实现了在单一自回归框架下的多模态统一。

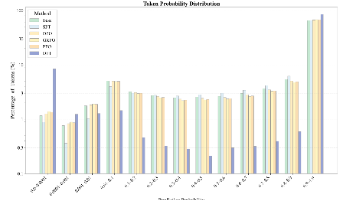
大语言模型(LLMs)在预训练之后,往往需要通过进行对齐与能力塑形。,它在梯度结构、泛化行为和表达学习方面存在缺陷。本文将从等角度,系统梳理它们之间的关系。
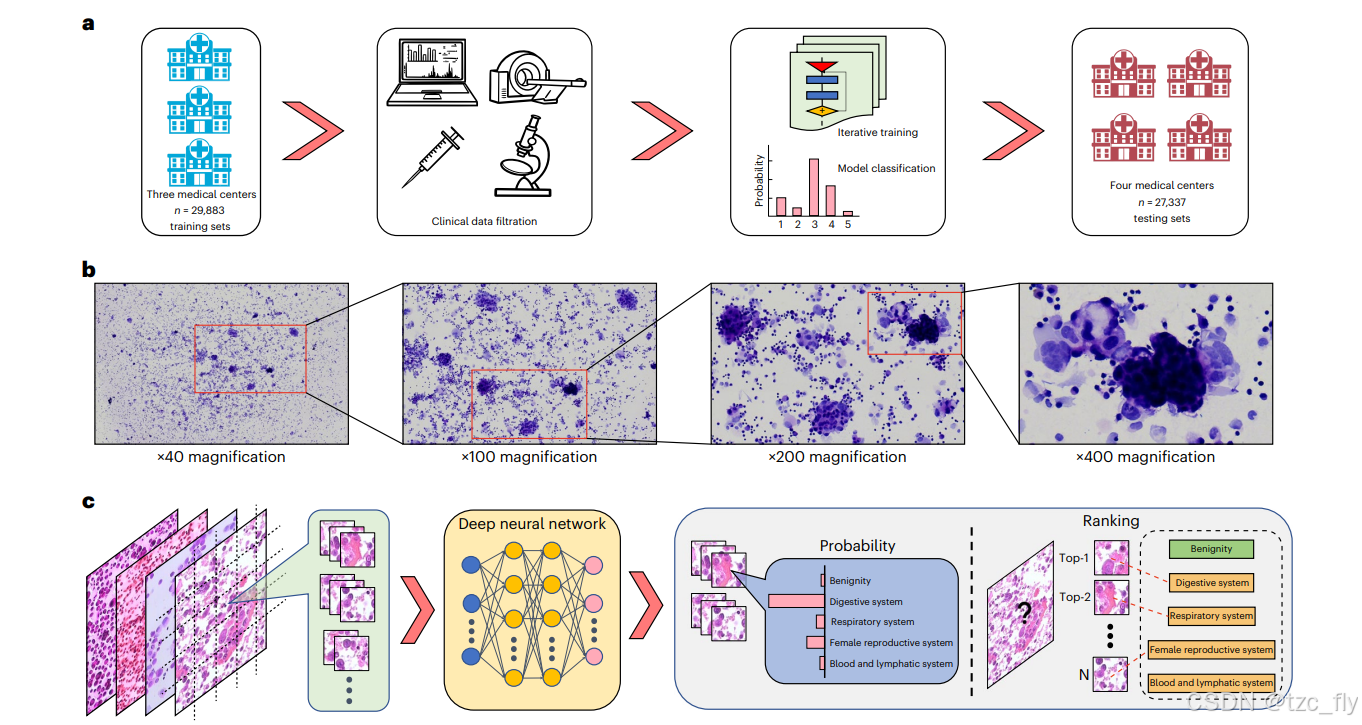
预测不明来源癌症的起源
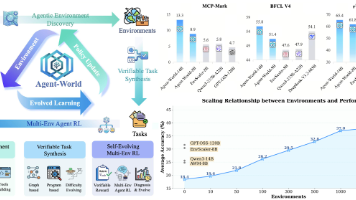
Agent-World:LLM与环境的协同进化
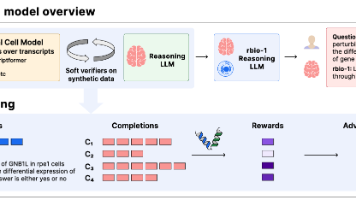
rbio1:以生物学世界模型为软验证器训练科学推理大语言模型
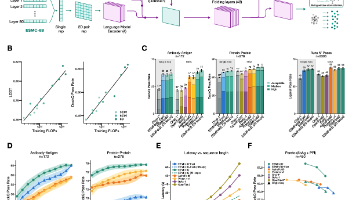
Candido 等人的这篇论文向世界宣告:蛋白质语言模型已经跨越了“统计拟合”的阶段,它在硅基世界里真正物质化(Materialize)了蛋白质生物学的基本物理和演化规律。这种通用、原子级精准且具备生命尺度演化视野的“世界模型”,不仅将虚拟数字实验的效率提升了数万倍,更深刻地证明了 AI 在没有人类先验知识的干预下,能够完全独立地重构并拓展人类数百年建立起来的经验生物学大厦。
Candido 等人的这篇论文向世界宣告:蛋白质语言模型已经跨越了“统计拟合”的阶段,它在硅基世界里真正物质化(Materialize)了蛋白质生物学的基本物理和演化规律。这种通用、原子级精准且具备生命尺度演化视野的“世界模型”,不仅将虚拟数字实验的效率提升了数万倍,更深刻地证明了 AI 在没有人类先验知识的干预下,能够完全独立地重构并拓展人类数百年建立起来的经验生物学大厦。
大语言模型(LLMs)在预训练之后,往往需要通过进行对齐与能力塑形。,它在梯度结构、泛化行为和表达学习方面存在缺陷。本文将从等角度,系统梳理它们之间的关系。
LLaDA2.0-Uni:基于扩散语言模型的统一多模态理解和生成