- @qq_37756660
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们这节深入地介绍了 malloc 方法的实现原理,并以一个例子来说明如何设计自己的动态内存管理器。通过这节课的学习,我们了解到 sbrk 和 mmap 是操作系统提供的系统调用,系统调用性能不够且不能对分配的内存进行有效管理,所以必须有人在用户态将大块的内存分割成小块,然后进行更精细的分配和回收,这个工作通常情况下是由 glibc 承担的。glibc 所提供的 malloc 在管理内存时,采用了
在这节中,我们从抽象到具体逐步了解了程序运行时的内存布局模型。我们了解到,一个进程的内存可以分为内核区域和用户区域。内核区域是由操作系统内核维护的,我们通常并不关心这一块内存是如何使用的。代码段保存的是程序的机器指令,这一段区域的内存往往是可读可执行,但不可写;数据段保存的是程序的静态变量和全局变量;bss 段用于无初值的变量区域;堆是程序员可以自由申请的空间,当我们在写程序时要保存数据,优先会选
在这节中,我们从抽象到具体逐步了解了程序运行时的内存布局模型。我们了解到,一个进程的内存可以分为内核区域和用户区域。内核区域是由操作系统内核维护的,我们通常并不关心这一块内存是如何使用的。代码段保存的是程序的机器指令,这一段区域的内存往往是可读可执行,但不可写;数据段保存的是程序的静态变量和全局变量;bss 段用于无初值的变量区域;堆是程序员可以自由申请的空间,当我们在写程序时要保存数据,优先会选
今天要与你分享的主题是“大规模数据处理在深度学习中如何应用?“深度学习”这个词,既是一个人工智能的研究领域,也概括了构建人工神经网络的技术方法。2012 年的 AlexNet,2015 年的 Google Inception V3 级数式地打破 ImageNet 计算机视觉比赛的最高纪录,2017 年亮相的 AlphaGo 更是掀起了全球的深度学习风暴。在 Google,深度学习系统被应用在预测广
在这次答疑中,希望通过深度分析 epoll 的源码实现,帮你理解 epoll 的实现原理。epoll 维护了一棵红黑树来跟踪所有待检测的文件描述字,黑红树的使用减少了内核和用户空间大量的数据拷贝和内存分配,大大提高了性能。
你在办公中,一定遇到过需要数据持久化的问题。数据持久化,简单来说,就是当你关闭程序的时候,数据依然可以完整地保存在电脑中。你可能会想到用文本文件、Excel 来存储这些数据,文本呢,没有办法按列读写数据,Excel 呢,支持的默认 API 无法进行复杂查询。所以我今天要给你介绍一个功能强大,但编写代码又简单的数据库 SQLite。你可以用 SQLite 存储结构化的数据,把程序的处理结果保存到电脑
迭代法,简单来说,其实就是不断地用旧的变量值,递推计算新的变量值。我这么说可能还是有一点抽象,不容易理解。我们还回到刚才的故事。大臣要求每一格的麦子都是前一格的两倍,那么前一格里麦子的数量就是旧的变量值,我们可以先记作;而当前格子里麦子的数量就是新的变量值,我们记作。这两个变量的递推关系就是这样的:如果你稍微有点编程经验,应该能发现,迭代法的思想,很容易通过计算机语言中的循环语言来实现。
从机器学习模型角度看,目前最简单的机器学习模型大概就是感知机了,而最火热的机器学习模型则是神经网络。人工智能领域几乎所有炫酷的东西都是神经网络的成果,有下赢人类最顶尖围棋棋手的 AlphaGo、自动驾驶技术、聊天机器人、语音识别与自动翻译等。事实上,神经网络和感知机是一脉相承的,就像复杂的人体是由一个个细胞组成、复杂的大脑是由一个个神经元组成,而神经网络正是由感知机组成的。
神经网络是非参数模型的一种,它利用激活函数对线性模型做出了非线性的扩展,让每个输出变成了权重系数的非线性函数,从而在整体上拟合出非线性的效果。感知器的初始参数是随机生成的,用这组随机参数生成的分类边界是图中的红色虚线。在之后的每一轮训练中,训练结果在验证集上的性能都被拿来和先前存储的模型性能进行比较,之后保留两者中表现较好的模型的配置。神经网络中隐藏神经元的数目决定着网络的泛化性能,足够多的神经元
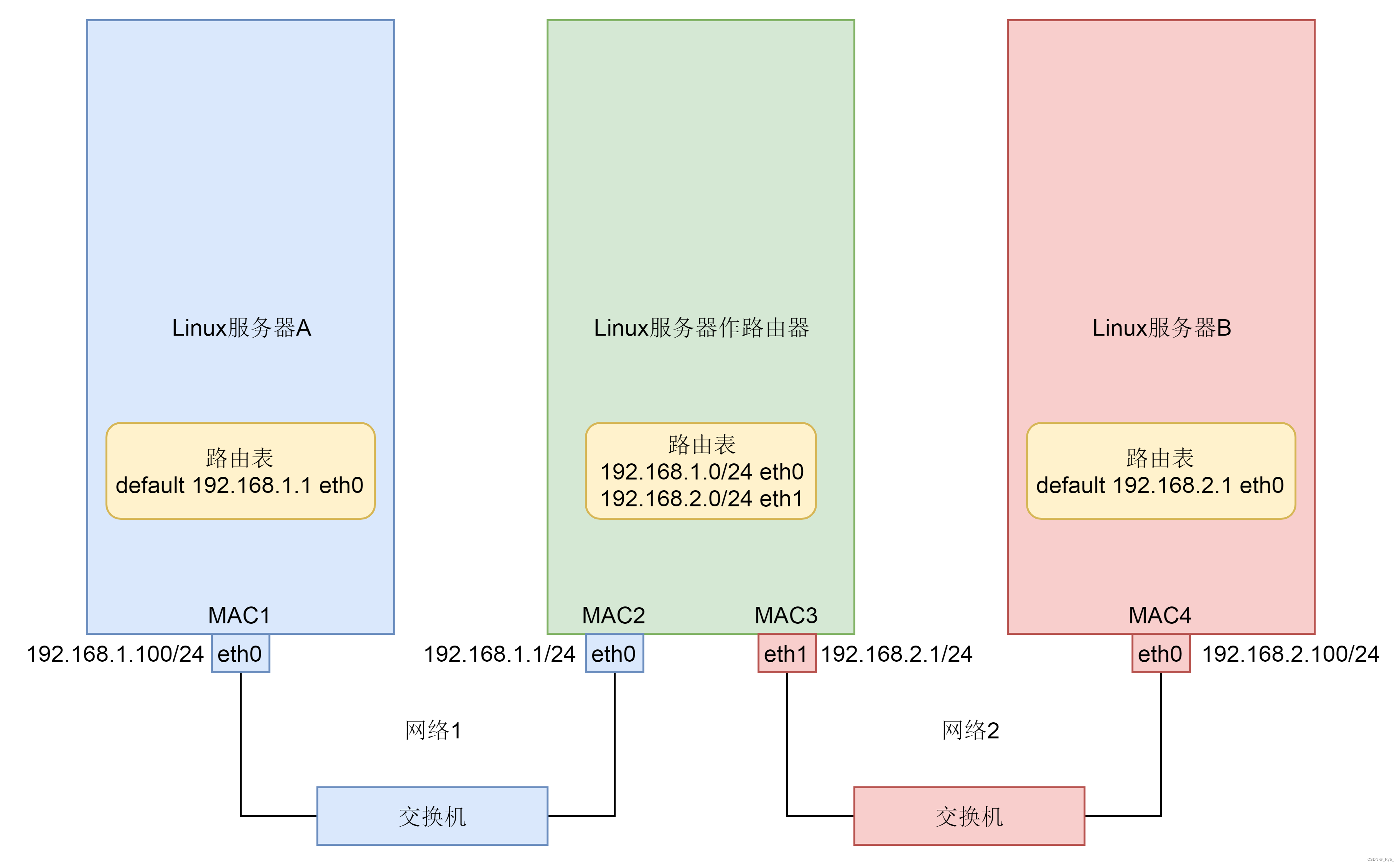
网络协议是一个大话题,这个专栏重点解析在这个网络通信过程中,发送端和接收端的操作系统都做了哪些事情,对于中间通路上的复杂的网络通信逻辑没有做深入解析。如果只是为了掌握这一章的内容,只要记住 TCP/UDP->IPv4->ARP 这一条链就可以了,因为后面的分析都是重点分析这条链。