




- @qq_37335220
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大数据采集是指从传感器和智能设备、企业在线系统、企业离线系统、社交网络和互联网平台等获取数据的过程。数据数据包括RFID数据、传感器数据、用户行为数据、社交网络交互数据及移动互联网数据等各种类型的结构化、半结构化及非结构化的海量数据。大数据的分类业务数据:消费者数据、客户关系数据、库存数据、账目数据等。行业数据:车流量数据、能耗数据、PM2.5数据等。内容数据:应用日志、电子文档、机器数据、语音数
大数据采集是指从传感器和智能设备、企业在线系统、企业离线系统、社交网络和互联网平台等获取数据的过程。数据数据包括RFID数据、传感器数据、用户行为数据、社交网络交互数据及移动互联网数据等各种类型的结构化、半结构化及非结构化的海量数据。大数据的分类业务数据:消费者数据、客户关系数据、库存数据、账目数据等。行业数据:车流量数据、能耗数据、PM2.5数据等。内容数据:应用日志、电子文档、机器数据、语音数
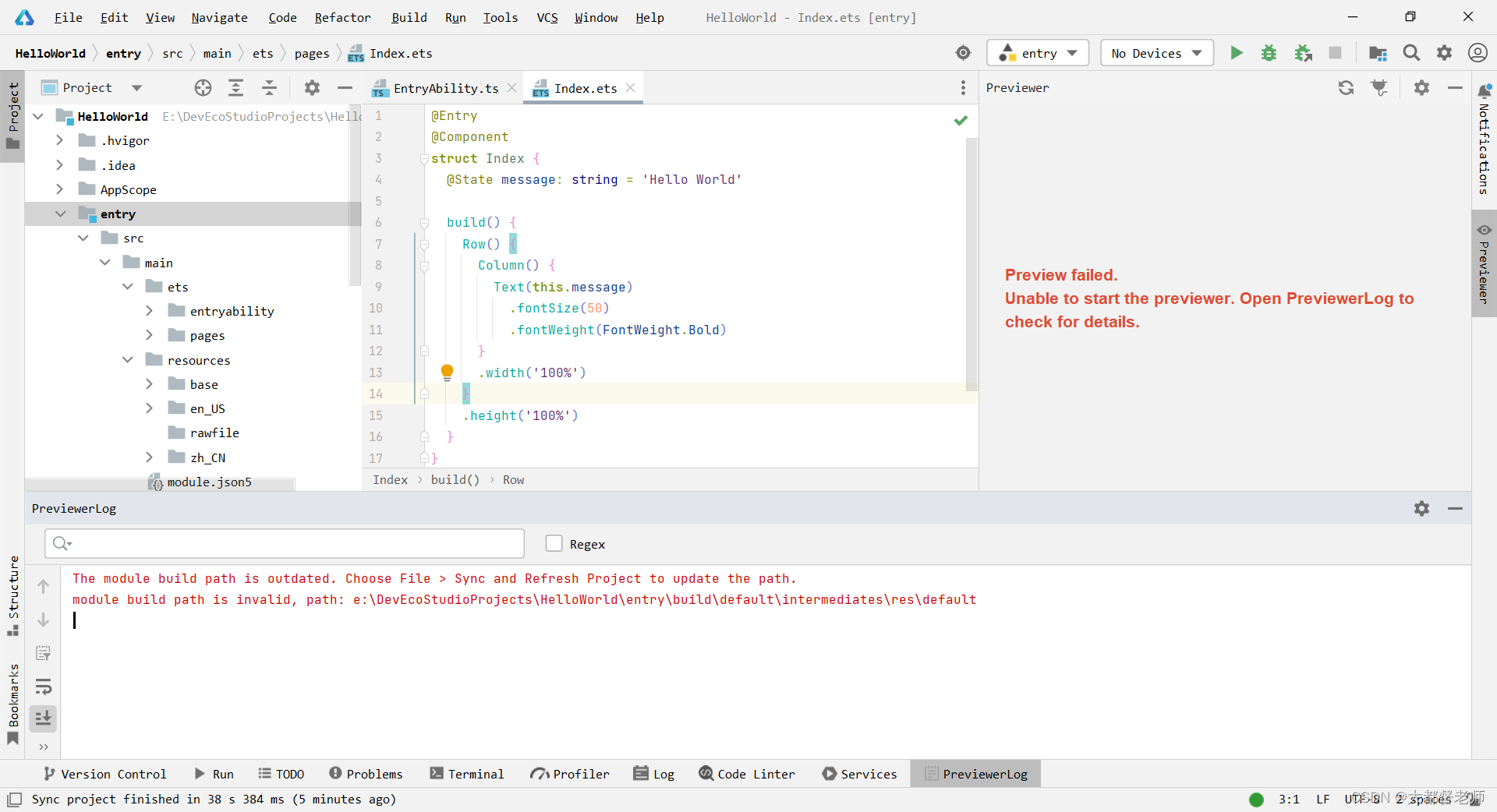
报错截图:解决方案:卸载idea,重新安装idea、sdk、nodejs、ohpm(主要原因就是版本不兼容的问题,我这里是nodejs版本问题,按照推荐重装后),问题解决!!!
报错如下:解决办法:报错原因:因为浏览器不能直接加载本地资源解决办法:1.创建一个Server服务器端,目录结构如下:2.检查资源加载方式是否正确,正确的加载方式如下:验证再次在浏览器中访问,结果正常加载资源,效果如下:...
接下来我们开始讲解Ceph的概述,这一块主要涉及了4个小节,分别是Ceph的产生背景、Ceph的简介、Ceph的特点以及通过与其他分布式存储系统进行横纵对比后,得出Ceph有哪些优缺点。先来看Ceph的产生背景… …接下来,我们开始讲解Ceph的简介,Ceph是一个可靠的、自动重均衡、自动恢复的分布式存储系统。其存储场景非常的丰富,支持对象存储、块设备存储、文件系统服务。
Scrapy是一个为了爬取网站数据、提取结构性数据而编写 的应用框架,可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。Scrapy架构Scrapy的整体架构由Scrapy引擎(Scrapy Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(Spiders)和数据项管道(Item Pipeline)5个组件和两个中间件构成。Scrapy引擎(Scra
① 访问官方网址下载 MediaCreationTool22H2.exe② 下载 Windows 10 iso 镜像③
java: 读取D:\Maven\repository\com\fasterxml\jackson\dataformat\jackson-dataformat-smile\2.11.4\jackson-dataformat-smile-2.11.4.jar时出错; error in opening zip file
去掉idea中有些代码的黄色背景alt+enter,翻译下拉的英文选项,点击>,选择 “disable”即可。去掉标记为过时的方法横线方法同上,需要知道下拉选项的英文含义。
在合适工具的辅助下,对广泛异构的数据源进行抽取和集成,将结果按照一定的标准进行统一存储,然后利用合适的数据分析技术对存储的数据进行分析,从中提取有益的知识,并利用恰当的方式将结果展现给终端用户。数据抽取与集成对所需数据源的数据进行抽取和集成,从中提取出数据的实体和关系,经过关联和聚合之后采用统一定义的结构来存储这些数据。在数据集成和提取时,需要对数据进行清洗,保证数据质量及可信性。数据抽取与集成方