- @qq_36372352
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
KITTI 3D 数据可视化不仅限于将点云转换为图像或模型,它还涉及复杂的数据处理和分析,包括传感器标定、坐标变换等。通过这些高级技术,研究人员和工程师能够更好地理解和开发用于自动驾驶车辆的算法和系统。随着技术的不断进步,我们预期这些可视化工具将变得更加精准和高效,为未来的自动驾驶技术铺平道路。通过本文的详细介绍,我们可以看到3D数据可视化在自动驾驶研究中的重要性,以及如何通过齐次变换、点云处理和

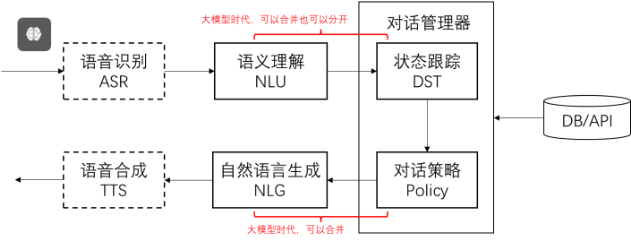
在 API 调用中,您可以描述函数,并让模型智能地选择输出包含调用一个或多个函数的参数的 JSON 对象。Chat Completions API不会调用该函数;相反,模型会生成 JSON,您可以使用它来调用代码中的函数。本指南重点介绍使用聊天完成 API 进行函数调用,有关助手 API 中函数调用的详细信息,请参阅助手工具页面。
在 GitHub 上,转到你的仓库,点击“Pull requests”,然后点击“New pull request”。选择你刚推送的分支与主分支进行比较,并点击“Create pull request”。首先,你需要将远程仓库克隆到你的本地机器上。在 GitHub 上找到你想要克隆的仓库,点击“Clone or download”,复制仓库的 URL。如果审查通过,维护者将合并你的 PR 到主分支

如果您不熟悉合并冲突的解决,可以查看 VSCode 的帮助文档或求助于更有经验的同事。解决此类冲突可能需要您对项目结构和变更历史有一定的了解,以做出恰当的决策。:冲突的部分会标记为“当前更改”(HEAD)和“传入更改”(即远程分支的更改)。此过程允许您将不同分支(远程或本地)的更改集成到您当前的工作分支中。:首先,确保您的本地仓库包含了远程仓库所有分支的最新信息。:当合并产生冲突时,VSCode
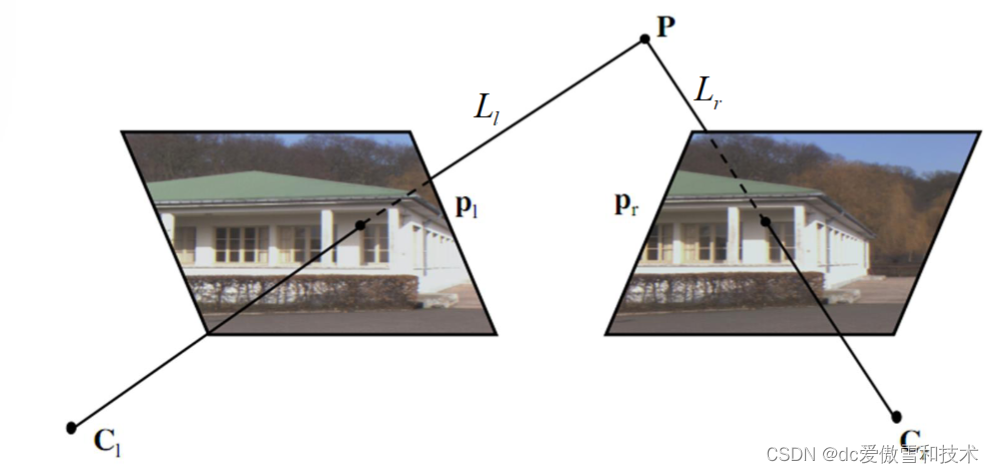
立体视觉=对应+重建:• 对应:给定一幅图像中的点pl,找到另一幅图像中的对应点pr。• 重建:给定对应关系(pl, pr),计算空间中相应点的3D 坐标P。立体视觉:从图像中的投影恢复场景中点的三维位置的过程类型:基于窗口/局部的算法和全局算法三角测量:给定pl,我们知道点P位于连接pl和左光心Cl的直线Ll上。**假设我们确切地知道相机的参数,我们可以显式计算 Ll 和 Lr 的参数。**因此
双向Dijkstra算法:这种变体从源点和目标点同时运行Dijkstra算法,直到两个搜索相遇。这可以在某些情况下减少需要探索的顶点和边的数量。双向A*算法:与双向Dijkstra类似,双向A*从两个方向搜索,并利用启发式函数来加速搜索过程。这通常可以进一步减少搜索空间和时间。时间依赖的路径规划:这些算法变体考虑了动态变化的边权重(如交通条件)。它们使用更复杂的数据结构来适应时间依赖性,以提供实时

通过这些命令和工具,你可以开始在你的系统上使用 Docker 来运行和管理各种容器化的应用程序。Docker 提供了一个强大的平台,用于开发、测试和部署应用程序,使其在不同环境中具有一致的行为。安装这些包之后,你可以开始使用 Docker 来创建和管理容器。

有一个与使用语言模型相关的整个领域,被称为“提示工程”,但随着该领域的发展,其范围已经超出了仅仅将提示工程设计为使用模型查询作为组件的工程系统的范围。这些模型的输入也称为“提示”。但请注意,对于某些模型,输入中的代币与输出中的代币的每个代币的价格是不同的(有关更多信息,请参阅定价。但请注意,系统消息是可选的,没有系统消息的模型行为可能类似于使用通用消息,例如“你是一个有用的助手”。等聊天模型使用令
提示工程也叫「指令工程」。Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等貌似简单,但意义非凡「Prompt」 是 AGI 时代的「编程语言」「Prompt 工程」是 AGI 时代的「软件工程」「提示工程师」是 AGI 时代的「程序员」学会提示工程,就像学用鼠标、键盘一样,是 AGI 时代的基本技能提示工程「门槛低,天花板高」
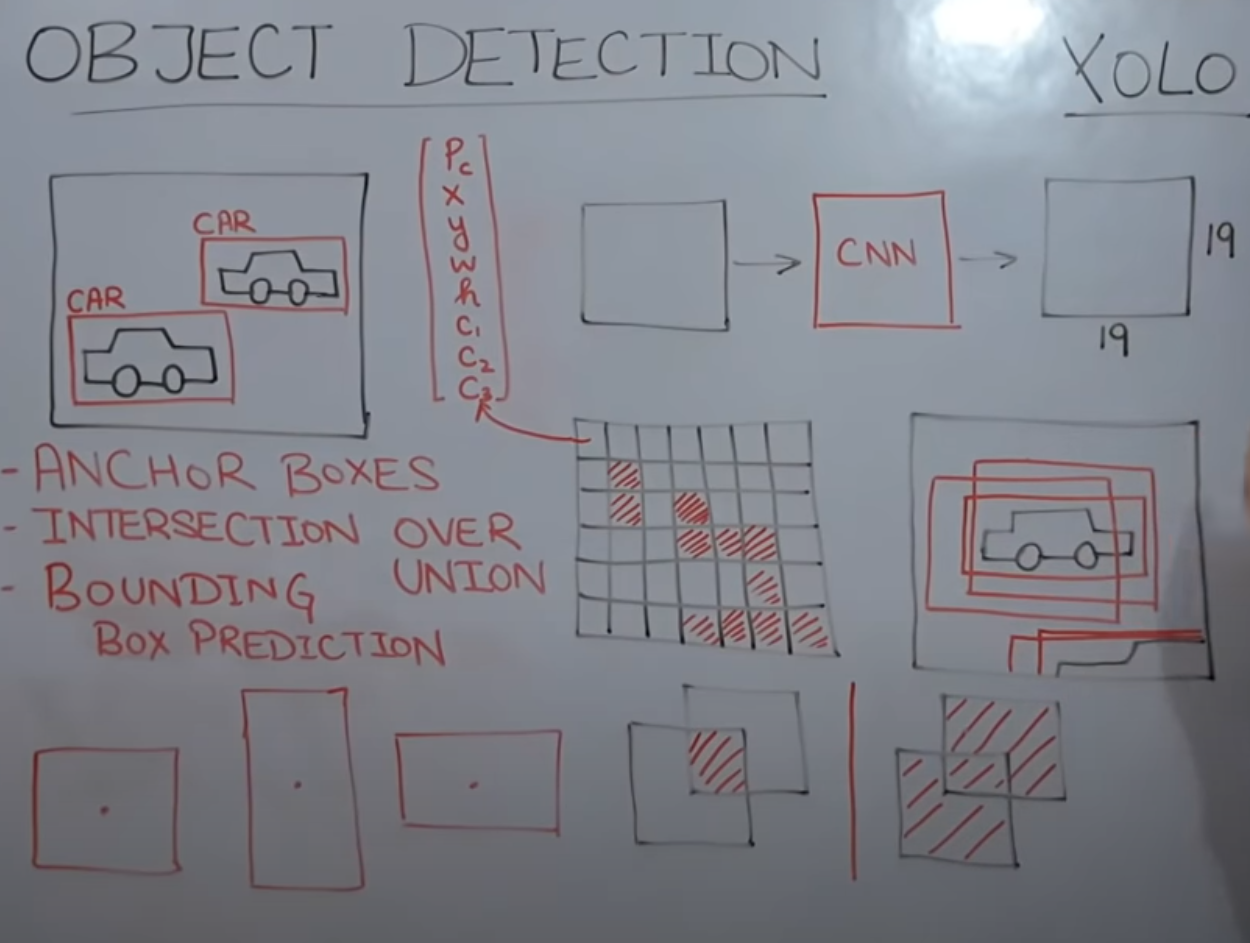
yolo及yolo的变体anchor boxes (锚框)intersection over union 并集交集用于计算两个边界框的差异程度bounding box predictions 边界框预测non maximum suppression非极大值抑制为了分离这些边界框并为每个对象获得单个边界框,我们使用IOU。这种获取单个边界框并分离不同边界框的技术称为非极大值抑制。分别对这些边界框应用