




- @qq_33816117
简介
代码工程师
擅长的技术栈
可提供的服务
架构设计
本文介绍了使用WorkBuddy工具快速开发微信小程序的全过程。首先下载WorkBuddy并创建项目,通过AI生成健身助手小程序的代码框架;然后使用微信开发者工具导入项目目录进行调试,遇到错误时利用WorkBuddy自动修复;最后提交微信公众平台审核。整个过程仅需半小时即可完成基础小程序开发,显著提升了开发效率。文章展示了AI辅助工具如何简化小程序开发流程,特别适合快速实现简单功能的小程序项目。
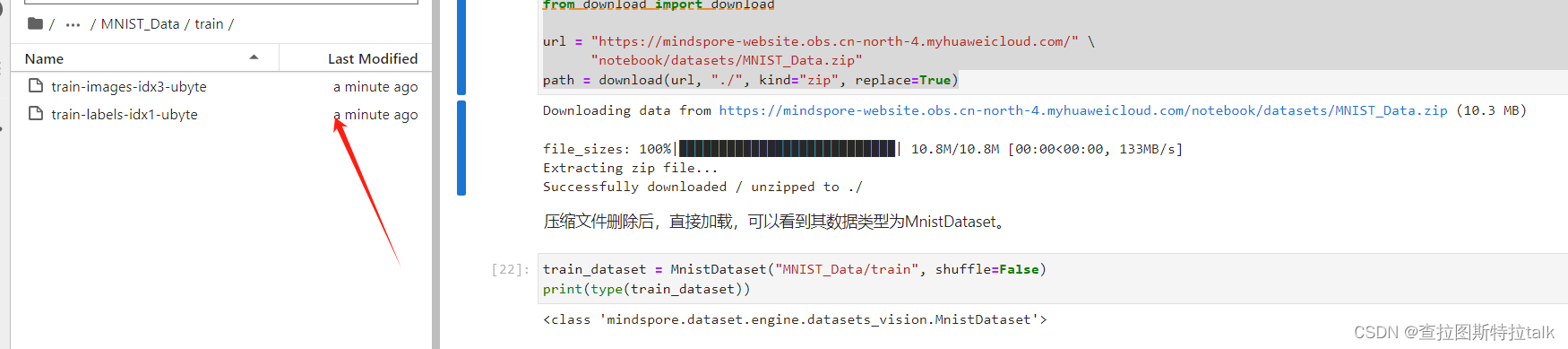
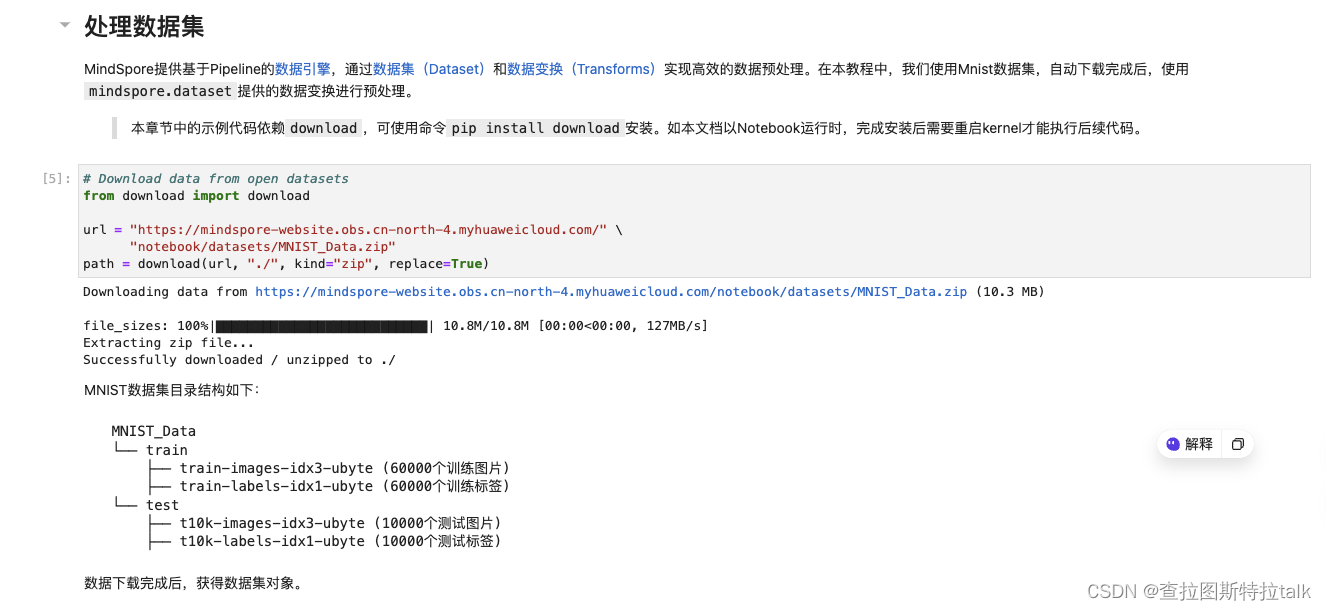
mindspore.dataset模块提供了加载常用公开数据集和标准格式数据集的API。对于MindSpore暂不支持直接加载的数据集,可以通过构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器构造自定义数据集。这一节主要是针对数
本文介绍了使用WorkBuddy工具快速开发微信小程序的全过程。首先下载WorkBuddy并创建项目,通过AI生成健身助手小程序的代码框架;然后使用微信开发者工具导入项目目录进行调试,遇到错误时利用WorkBuddy自动修复;最后提交微信公众平台审核。整个过程仅需半小时即可完成基础小程序开发,显著提升了开发效率。文章展示了AI辅助工具如何简化小程序开发流程,特别适合快速实现简单功能的小程序项目。
本文介绍了使用WorkBuddy工具快速开发微信小程序的全过程。首先下载WorkBuddy并创建项目,通过AI生成健身助手小程序的代码框架;然后使用微信开发者工具导入项目目录进行调试,遇到错误时利用WorkBuddy自动修复;最后提交微信公众平台审核。整个过程仅需半小时即可完成基础小程序开发,显著提升了开发效率。文章展示了AI辅助工具如何简化小程序开发流程,特别适合快速实现简单功能的小程序项目。
简单的理解这个过程,首先加载数据集,配置网络,然后进行模型训练,经过不断的训练提高准确度,尝试去保存模型,方便下次使用,然后试着加载模型。看看实际操作结果如果。整个过程顺风顺水还是非常方便的操作。
Grover搜索算法是量子计算中一种利用量子状态的叠加性进行并行计算并实现加速的算法。无序数据库搜索问题是Grover搜索算法解决的问题,该算法能以平方加速度找到目标元素。Grover搜索算法通过振幅放大的方法来提高找到目标态的概率。龙算法是在Grover算法基础上改进的量子精确搜索算法,能精确找到目标态。

BERT是一种由Google于2018年发布的新型语言模型,它是基于Transformer中的Encoder并加上双向的结构。BERT模型采用了Masked Language Model和Next Sentence Prediction两种方法进行预训练,以捕捉词语和句子级别的representation。预训练之后,BERT可以用于下游任务的Fine-tuning,比如文本分类、相似度判断等。此

使用mindnlp库实现GPT2模型进行文本摘要,采用BertTokenizer进行分词, 使用线性预热和衰减的学习率策略进行模型训练. 通过多种数据预处理和模型优化技术, 训练并部署模型进行文本摘要推理.

在情感分类任务中,首先通过`load_dataset`函数加载IMDB数据集,该数据集分为训练集和测试集,以确保有效利用标注好的电影评论进行模型训练和评估。在此过程中,还对数据进行预处理,包括去除无关字符和标准化文本格式,以提高模型效果。接下来,使用GPT Tokenizer对IMDB数据集中的评论进行分词,这一过程不仅将文本分割成单词或子词,还添加必要的特殊标记,如开始标记(<bos>)和结束标

简单的理解这个过程,首先加载数据集,配置网络,然后进行模型训练,经过不断的训练提高准确度,尝试去保存模型,方便下次使用,然后试着加载模型。看看实际操作结果如果。整个过程顺风顺水还是非常方便的操作。