




- @qq_33328642
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
TP: 将正类预测为正类数FN: 将正类预测为负类数FP: 将负类预测为正类数TN: 将负类预测为负类数准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN)精确率(precision) = TP/(TP+FP)召回率(recall) = TP/(TP+FN)f-score = 精确率 * 召回率 * 2 / (精确率 + 召回率)举个例子最近正好做 男女儿
主要是一些深度强化学习算法的调参技巧
定义6(样本效率)。在深度强化学习任务中, 样本效率即利用有限的交互次数,通过合理的策略与环境交互进行采样,并利用采样数据进行训练,以获取策略优化的指标。评估算法的样本效率,既可以在使用相同交互次数的前提下衡量动作策略的训练效果,也可以在到达相同训练效果的前提下衡量达到此效果所需的交互采样次数。由于在强化学习算法中,智能体以当前策略与环境交互进行采样,并利用已得到的样本数据对策略进行优化,探索过程

关于DQN算法的一些细节,可以查看这个博客,讲的很细节。主要参考博客https://zhuanlan.zhihu.com/p/443807831https://itpcb.com/a/162740#:~:text=%E5%87%BA%E7%8E%B0%E4%BB%B7%E5%80%BC%E9%AB%98%E4%BC%B0%E7%9A%84%E6%A0%B9,%E7%9A%84%E5%8D%B7%E
大概摘要了多任务强化学习和多智能体强化学习的一些方法
1. Q-learning1.1 Q-learning概述Q-Learning 是 Deep Q Learning 的基础。Q 学习算法使用状态动作值(也称为 Q 值)的 Q 表。这个 Q 表对每个状态有一行,对每个动作有一个列。每个单元格包含相应状态-动作对的估计 Q 值。我们首先将所有 Q 值初始化为零。当agent与环境交互并获得反馈时,算法会迭代地改进这些 Q 值,直到它们收敛到最优 Q
这篇文章是从这个博客转载来的https://www.jianshu.com/p/1d23bcc1a620算法思路拟合局部的是时变线性动态模型,而不是学习一个全局模型。在全局动态模型复杂非线性并且不连续的情况下, 很难被成功学习(采集到的样本不足以充分反映系统动态分布)。该算法是model-based和model-free的混合方法,比model-free方法需求更少的样本,又能很好的解决model
结构体详解结构体是不同数据类型的集合。结构体的好处:1)我们在写一个关于管理学生信息的代码,如果我们有4000个学生要管理。我们要管理他们的姓名,学号,电话号码,身份证,父母姓名,父母电话这些信息。如果按照普通方法,我们要创建6*4000 = 24000这么多的变量,然而事实上这是不可能的,到时候直接能把你累秃了。2)Ok!如果有的同学说,不怕,不久24...
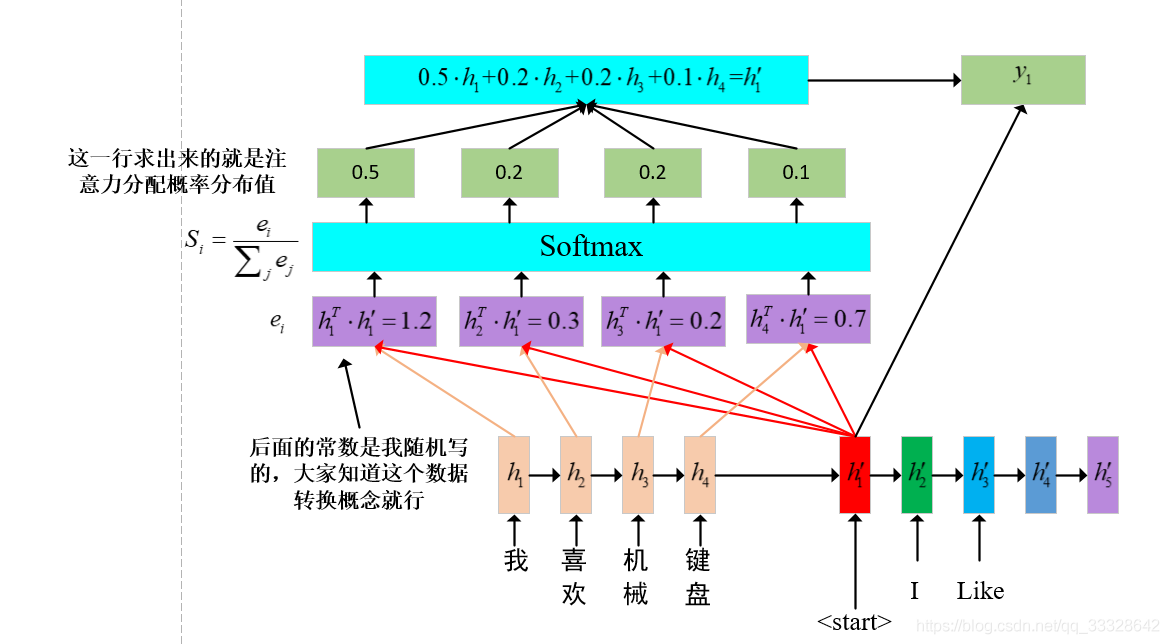
1。 序言首先呢,我是看这两篇片文章的。但是呢,他们一个写的很笼统,一个是根据Encoder-Decoder和Query(key,value)。第二个讲的太深奥了,绕来绕去,看了两天才知道他的想法。https://segmentfault.com/a/1190000014574524这个是讲的很笼统的https://blog.csdn.net/qq_40027052/article/details
规划场景Planning Scene该PlanningScene类提供的主界面,你将用于碰撞检测和约束检查。设置所述PlanningScene类可以很容易地安装和使用配置的RobotModel或URDF和SRDF。但是,这不是实例化PlanningScene的推荐方法。 建议使用PlanningSceneMonitor,该方法使用来自机器人关节和机器人上传感器的数据来创建和维护当前计划场景(在下一