




- @qq_20466211
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DBeaver连接IoTDB

容器化安装linux
Yaml:基本语法使用YAML 入门教程YAML在线编辑链接1 简介YAML 的意思其实是:“Yet Another Markup Language”(仍是一种标记语言)。YAML的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲(例如:许多电子邮件标题格式和YAML非
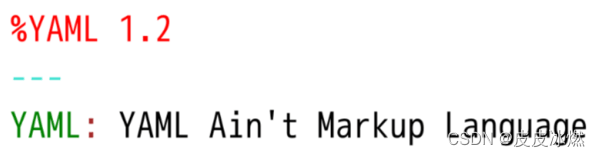
适用于本地化、集群、边缘计算和物联网的几款轻量级K8s:MicroK8s、K3s和K0s1 安装snapdcat /etc/centos-release查看centos版本yum install epel-release安装EPEL库yum install snapd安装snapd库systemctl enable --now snapd.socketln -s /var/lib/snapd/sn

1 Windows相关配置1.1 启用虚拟化打开任务管理器-> 选择性能 -> CPU ->虚拟化,确认是否已启用。1.2 启用Hyper-v控制面板-> 程序 -> 启用或关闭Windows功能 -> 勾选Hyper-v。启用Hyper-V后,VirtualBox就无法在使用。 但是,将保留所有现有的VirtualBox VM映像。3 Docker deskt
如何正确使用pyspark将数据发送到kafka经纪人?从kafka主题中接收数据,对该数据进行一些转换,然后将转换后的数据放在另一个kafka主题中。1 参数写在代码里#encoding=utf8from pyspark import SparkConf, SparkContextfrom operator import addimport sysfrom pyspark.streaming i
1 GitHub是什么参考GitHub官网归属公司:微软公司GitHub是一个面向开源及私有软件项目的托管平台,因为只支持git作为唯一的版本库格式进行托管,故名GitHub。GitHub于2008年4月10日正式上线,除了Git代码仓库托管及基本的 Web管理界面以外,还提供了订阅、讨论组、文本渲染、在线文件编辑器、协作图谱(报表)、代码片段分享(Gist)等功能。目前,其注册用户已经超过350
1 手动安装seafile#cat /etc/centos-releaseCentOS Linux release 7.8.2003 (Core)2 docker安装seafile参考官网用Docker部署Seafile宿主机centos7操作系统IP地址10.23.241.2022.1 安装 docker-compose因为 Seafile v7.x.x 容器是通过 docker-compose
1 DBeaverDBeaver的官网 https://dbeaver.io/download/DBeaver连接ClickHouse需要开放远程访问权限。(1)查看ClickHouse server端监听端口的状态:#lsof -i :8123这里显示监听本地端口localhost,需要修改配置:(2)#vi /etc/clickhouse-server/config.xml将注释去掉(3)重启
不需要在windows系统中安装spark。直接使用IntellIj IDEA下载相关依赖,开发即可。(1)添加spark的依赖val sparkVersion = "2.4.5"libraryDependencies += "org.apache.spark" % "spark-core_2.11" % sparkVersionlibraryDependencies += "org.apache