




- @qq_16164711
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
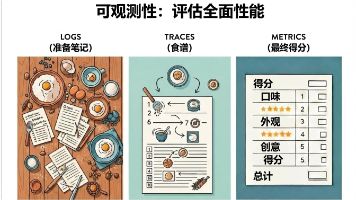
在 AI 智能体(Agent)技术飞速发展的今天,如何让具备自主性与非确定性的智能体突破传统软件质量模型的局限,成为企业可信赖的工具?本文将整合白皮书核心内容,拆解智能体质量保障的 “飞轮体系” 与三大核心原则,为落地企业级智能体提供行动蓝图。飞轮的第一步是锁定目标 —— 以 “四大质量支柱” 为具体标准,而非抽象的 “好与坏”。例如,为客服智能体设定 “有效性” 指标为 “用户问题解决率≥90%
AI Agent 定义:Model(模型) TOOLS(工具) Orchestration-Layer(编排) Runtime -Services (运行服务) 四个要素的结合。Model(大脑): 处理信息、评估选项、做出抉择Tools(双手): API拓展、调用代码函数、与外部知识(数据库)连接Orchestration Layer(神经系统): 任务规划(React)、管理记忆、决策调度(t
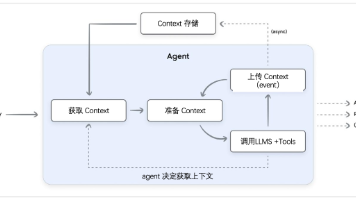
*核心主题:**聚焦上下文工程(),明确其两大核心组成部分为 “会话(Sessions)” 与 “记忆(Memory)”,强调该工程通过将对话历史、记忆、外部知识等必要信息动态整合到 LLM 的上下文窗口中,实现从简单对话交互到持久化、可行动智能的转化,且整个过程依赖会话与记忆两大系统的相互作用。核心角色:负责 “当下” 交互,是单轮对话的低延迟、按时间顺序排列的容器。主要挑战:需平衡性能与安全
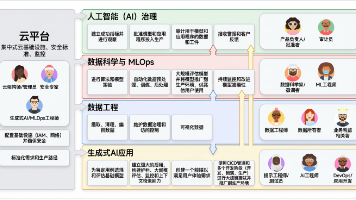
将 AI 原型落地为生产系统,本质是一场需要新运营规范 ——AgentOps 支撑的组织变革。多数 AI 智能体项目折戟 “最后一公里”,根源并非技术不足,而是自主系统的运营复杂性被低估。要弥合这一差距,需遵循清晰路径:先以 “人员与流程” 筑牢治理根基;再靠 “评估控制部署” 的预生产策略,实现高风险发布自动化;上线后,通过 “观察→行动→进化” 循环,把每次用户交互转化为优化洞见以备后续优化;
在 AI 智能体(Agent)技术飞速发展的今天,如何让具备自主性与非确定性的智能体突破传统软件质量模型的局限,成为企业可信赖的工具?本文将整合白皮书核心内容,拆解智能体质量保障的 “飞轮体系” 与三大核心原则,为落地企业级智能体提供行动蓝图。飞轮的第一步是锁定目标 —— 以 “四大质量支柱” 为具体标准,而非抽象的 “好与坏”。例如,为客服智能体设定 “有效性” 指标为 “用户问题解决率≥90%
*核心主题:**聚焦上下文工程(),明确其两大核心组成部分为 “会话(Sessions)” 与 “记忆(Memory)”,强调该工程通过将对话历史、记忆、外部知识等必要信息动态整合到 LLM 的上下文窗口中,实现从简单对话交互到持久化、可行动智能的转化,且整个过程依赖会话与记忆两大系统的相互作用。核心角色:负责 “当下” 交互,是单轮对话的低延迟、按时间顺序排列的容器。主要挑战:需平衡性能与安全
name:工具的唯一标识符title(可选) :用于显示的人类可读名称:人类&模型可理解的功能说明:JSON结构的入参说明(可选):JSON结构的出参说明(可选):描述工具行为的属性name和为核心参数,决定了 Agent 发现并调用 Tool 的时机和效果。"title": "股票价格查询工具","description": "根据特定股票代码查询股票价格。若提供“date”(日期)参数,则返回
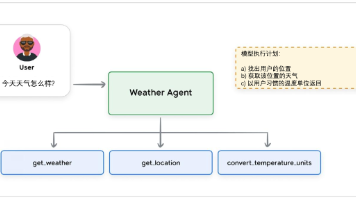
AI Agent 定义:Model(模型) TOOLS(工具) Orchestration-Layer(编排) Runtime -Services (运行服务) 四个要素的结合。Model(大脑): 处理信息、评估选项、做出抉择Tools(双手): API拓展、调用代码函数、与外部知识(数据库)连接Orchestration Layer(神经系统): 任务规划(React)、管理记忆、决策调度(t
当一项任务有特定的成功标准,但需要通过迭代来满足该标准时,评估器-优化器工作流通常会被采用。模型生成,模型评估,通过则结束,不通过则返回模型生成继续。: 具有预先确定的代码路径,并且设计为按特定顺序运行。Agent 通常是通过大型语言模型(LLM)借助。: 动态性,能自主定义自身流程和工具使用方式。, 一个模型决策,一个。
包含指令(instructions)脚本(scripts)资源(resources)的文件夹。指令:md文件中的文字指令脚本:python脚本或者bash命令资源:参考资料当Claude判定用户需求与某个Skill功能适配,就会加载阅读它的指令并执行脚本。它是对的一种约束和抽象,是对主agent执行某一特定任务的全方面指导。SKILL 是一种理念,一种规范:- 技术人员不要把它想的很简单(没有技术