




- @ordinary_brony
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果接触过计算机网络中的TCP/IP协议的话,你可能会对滑动窗口比较熟悉。那么滑动窗口到底是什么原理?在机器学习中又是如何运用?
在[上一篇文章](https://blog.csdn.net/ordinary_brony/article/details/149293790)中,我们完成了ChatOpenAI的实例化。接下来也就自然而然是使用它了。
本文介绍了如何通过微调千问大模型,使其具备个性化风格。作者基于8张5090显卡的环境,使用ms-swift工具和开源沐雪角色数据集进行全参数微调。文章详细说明了环境配置、依赖版本调整、数据集准备以及训练参数设置,并分析了损失函数的设计原理,重点阐述了因果遮罩和交叉熵损失在生成任务中的作用。最终训练结果显示模型能生成符合预期的个性化回答,同时指出适当调整batch_size可优化训练稳定性。
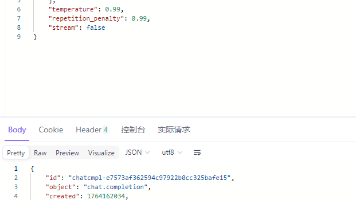
既然我们在前面的$9$篇文章中做了这么多事情,接下来就再加一点新东西:`LangGraph`。虽然说官方最新版本已经更新到了比较后面,支持`Runtime`的版本,但是我的项目已经有点积重难返了,所以只能使用早些时候不支持`Runtime`的版本了。代码库已经开源至[GitHub](https://github.com/sakebow/streamlit-tongyi),欢迎来玩。
既然MCP都已经出现了,甚至已经纳入面试题目了,就简单尝试一下这个新玩意儿。
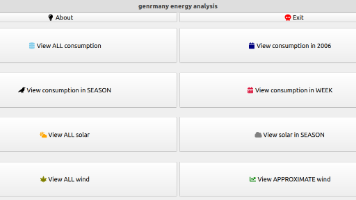
既然我们之前从用Qt学着做个界面中学到了最基本的GUI搭建方法,那就让我们结合研究生的数据分析日常,让我们来看看一个简单的数据分析界面应该怎么做。主要的分析步骤是根据数据酷客的案例的基础上加以改编,在这里这位佚名作者表示感谢。
一开始Vue生态还尚未完善的时候,Electron和其他框架很难整合。现在Vue生态逐步完善了,整合Electron也方便很多了。注:本篇将默认大家都会使用nodeJS。
本文介绍了如何通过微调千问大模型,使其具备个性化风格。作者基于8张5090显卡的环境,使用ms-swift工具和开源沐雪角色数据集进行全参数微调。文章详细说明了环境配置、依赖版本调整、数据集准备以及训练参数设置,并分析了损失函数的设计原理,重点阐述了因果遮罩和交叉熵损失在生成任务中的作用。最终训练结果显示模型能生成符合预期的个性化回答,同时指出适当调整batch_size可优化训练稳定性。
我们在之前的文章中学到了监督学习、非监督学习,现在就来看看强化学习,英文是Reinforcement Learning,也可以简写为RL。让我们来一探究竟,看看强化学习到底是怎么一回事。
在https://blog.csdn.net/ordinary_brony/article/details/150351142中,我们讨论了怎么在构建MCP。为了能够实现更复杂的功能,我们尝试将LangGraph引入到MCP中。