- @oYeZhou
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了LYT-Net,这是一个新颖的、轻量的、transformer-based的低光照图像增强模型,它由几个层和可拆卸的块组成,包括我们的新块——Channel-Wise Denoiser (CWD)和Multi-Stage Squeeze & Excite Fusion (MSEF)——以及传统的Transformer块,Multi-Headed Self-Attention (MHSA)
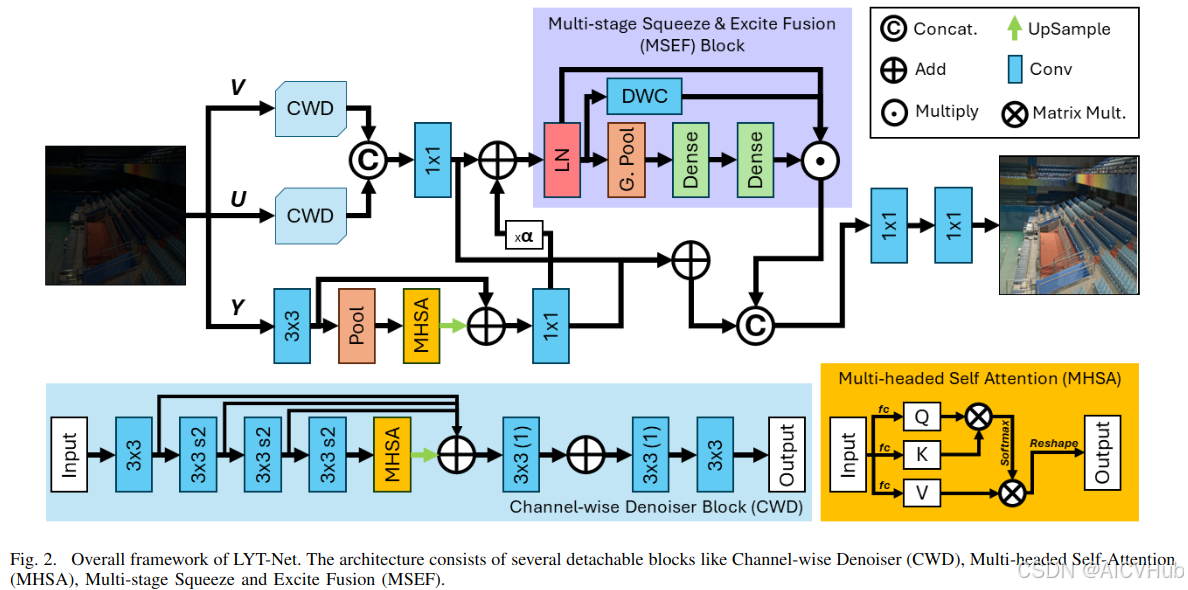
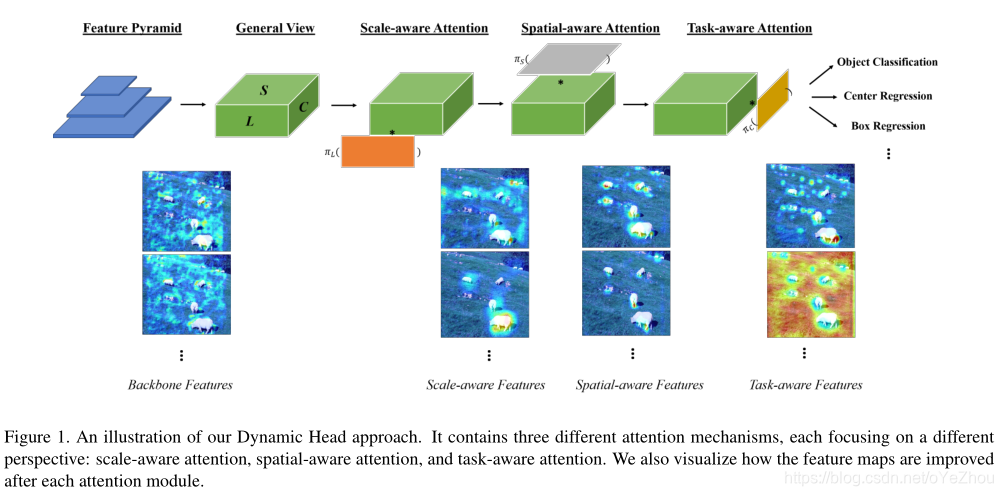
在目标检测方法中,由于分类和定位组合的复杂性,产生了多种多样的算法。这些算法尝试在检测heads上提升性能,不过它们缺乏一种统一的视角来看待检测问题。基于此,本文提出了一个新颖的动态head框架,将注意力机制与目标检测Heads统一起来。
介绍了Objects365数据集,并提供了百度网盘下载链接;同时,给出了数据集的统计信息。

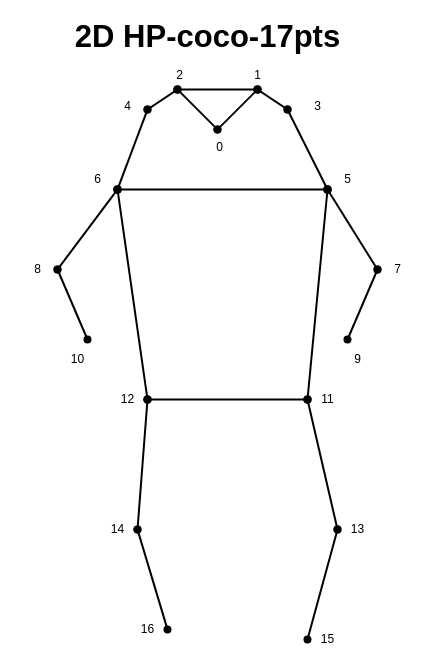
本文绘制了coco中人体姿态关键点的分布示意图,并解释了每个关键点的含义。
本文从实际的案例出发,介绍了如何在mmsegmentation使用自定义数据集和添加自定义模块,并介绍了安装过程的一些坑;供大家学习交流。

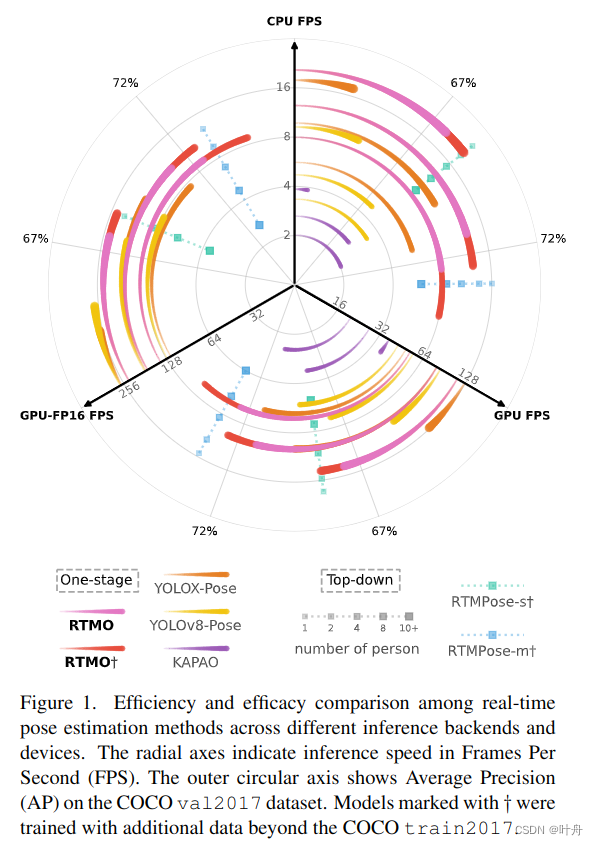
提出的RTMO框架如下图所示:网络框架描述如下:输入图像经过backbone(CSPDarknet)后,最后三层feature map经过Hybrid Encoder得到16、32倍下采样的空间feature mapP4、P5,送入Heads;每个Head生成一个得分feature、一个坐标姿态feature,其中坐标姿态feature用于预测bbox、关键点坐标、关键点可见性。****强行插入一
本文介绍了一种基于中文大模型和FLUX.1文生图模型的图像生成系统。该系统通过中文LLM将用户输入的中文提示词转换为专业英文提示词,再输入到FLUX.1模型生成图像
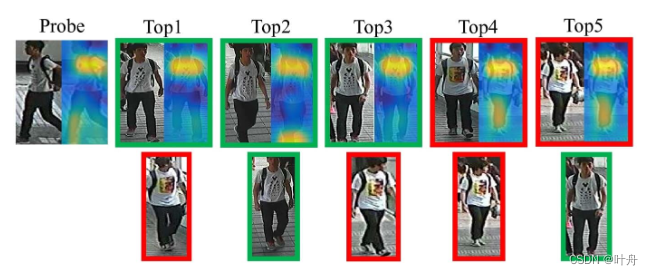
本文提供了一个从PA100K数据集中提取性别属性的方法。
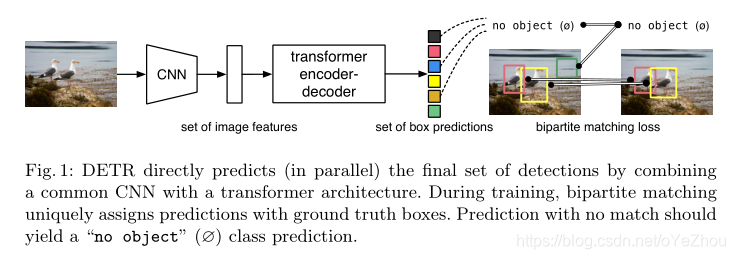
本文主要是基于transformers和双边匹配损失设计了一种新的目标检测范式——DETR,可以直接进行one-to-one预测。在COCO数据集上,DETR与高度优化的Faster RCNN性能相当。DETR应用简单,且拥有固定结构,可方便的扩展到全景分割等领域,并能达到不错的效果。此外,在大型目标的效果上, 是由于Faster RCNN的,这可能是因为DETR中的大量自注意力机制的应用使得模型
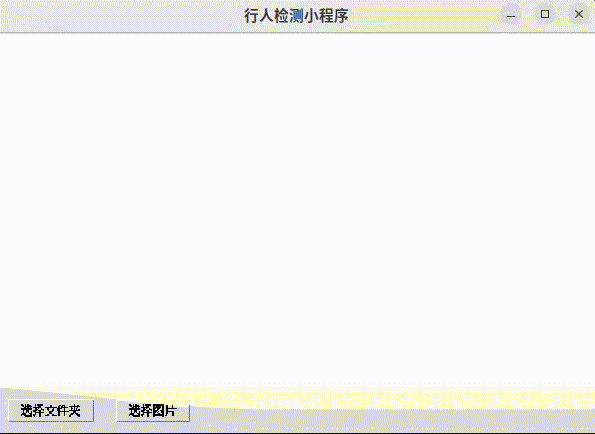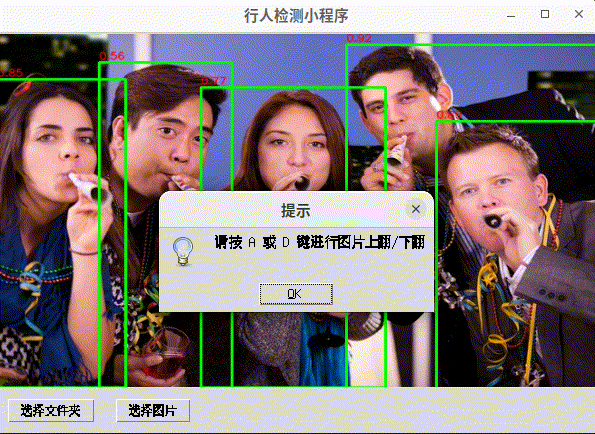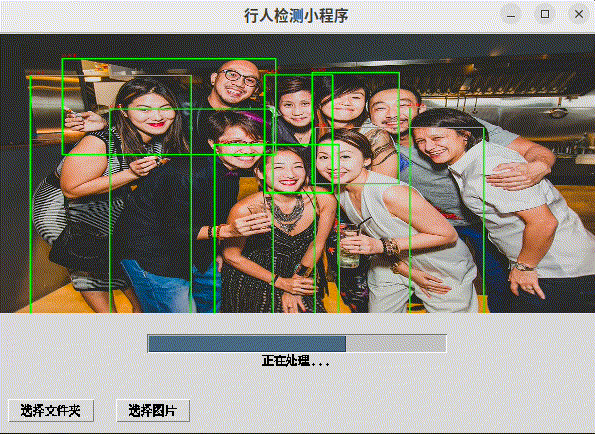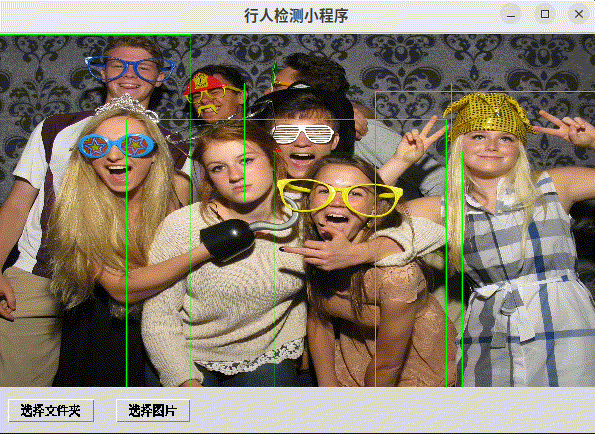
程序提供了一个用户友好的界面,允许用户选择图片或文件夹,使用行人检测模型进行处理,并在GUI中显示检测结果。用户可以通过点击画布上的检测结果来获取更多信息,并使用键盘快捷键来浏览不同的图片。