




- @ngadminq
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果出现没有的新的模型怎么部署,这个时候可以通过修改模型的config.json中model_type等操作,,但是一般都是不行的,本来就很难用还搞创新;为了排除是模型太大影响,我也尝试了切换到qwen3-0.5b,为了排除是显卡只支持FP16或只支持BFP16,我两种都尝试了。qwen3搜索后发现只有mindie2版本的支持,如果下成mindie1.X肯定是部署不上的;一直跟着执行,在安装驱动时
如果出现没有的新的模型怎么部署,这个时候可以通过修改模型的config.json中model_type等操作,,但是一般都是不行的,本来就很难用还搞创新;为了排除是模型太大影响,我也尝试了切换到qwen3-0.5b,为了排除是显卡只支持FP16或只支持BFP16,我两种都尝试了。qwen3搜索后发现只有mindie2版本的支持,如果下成mindie1.X肯定是部署不上的;一直跟着执行,在安装驱动时
如果出现没有的新的模型怎么部署,这个时候可以通过修改模型的config.json中model_type等操作,,但是一般都是不行的,本来就很难用还搞创新;为了排除是模型太大影响,我也尝试了切换到qwen3-0.5b,为了排除是显卡只支持FP16或只支持BFP16,我两种都尝试了。qwen3搜索后发现只有mindie2版本的支持,如果下成mindie1.X肯定是部署不上的;一直跟着执行,在安装驱动时
Ollama是一个开源的大语言模型管理平台,它允许用户在本地机器上部署、管理和使用各种开源语言模型。Ollama最出色的优点如下:将开源模型(如DeepSeek、Llama等)下载并部署到本地。从而让公司实现私有化+免费部署LLM。性能强大:充分利用本地资源,既可以使用GPU也可以使用CPU。如果没有Ollama,我们需要自己配置GPU环境如cuda等等,与传统的模型部署相比,Ollama大大简化

如果您可以装wsl,可以在本机部署因为笔者的windows电脑不可以安装wsl,所以本文会带大家在linux云服务器上部署。目前很多厂家都推出了一键部署,但是价格也有差阿里云 通用型服务器 70rmb/月华为云比较便宜,我这边选的服务器是西南贵州,成功部署大约。
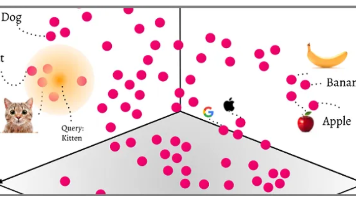
该指标体现Embedding模型在分类(Classification)、聚类(Clustering)、对分类(Pair Classification)、重排序(Reranking)、检索(Retrieval)等任务的表现。嵌入模型不仅能够编码词汇本身的含义,还能捕捉词与词之间、句子与句子之间的关联关系。这种语义相似性搜索是基于向量空间中的距离计算,而非简单的关键词匹配,能够更好地理解自然语言的语义
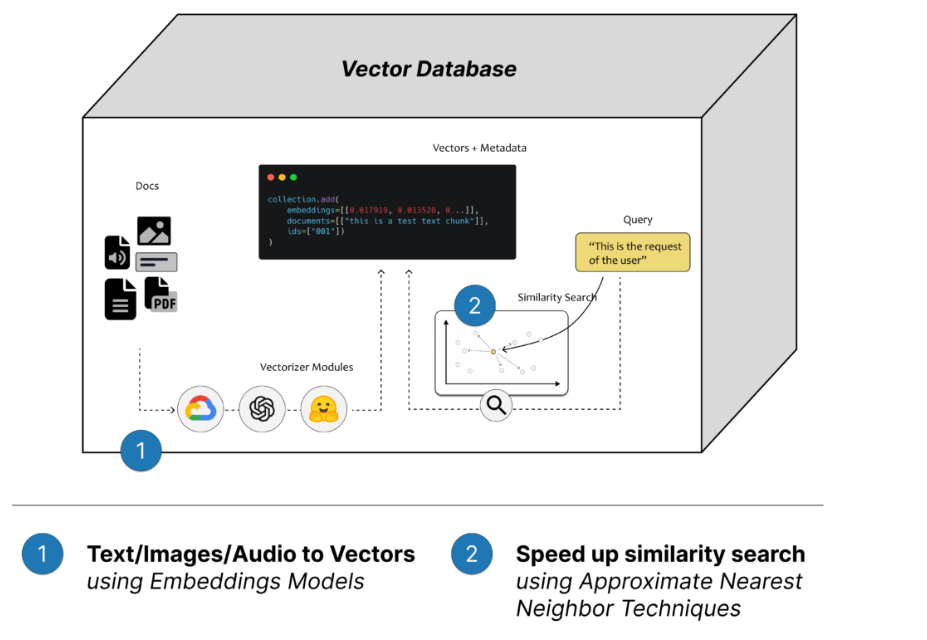
如何评估每种大模型需要多少GPU显存?本文给出方法与技巧

评估语言模型能力的基本思路是准备输入和标准答案,比较不同模型对相同输入的输出由于AI答题有各种各样答案,因此现在是利用选择题考察。有一个知名的选择题的基准叫做Massive Multitask Language Understanding (MMLU),里面收集了上万题的选择题那它的题目涵盖各式各样不同的学科。
